Aber eines Tages soll es das perfekte Python Buch für blutige Anfänger, die in Digital Humanities einsteigen wollen, werden.

Dieses Buch ist für all diejenigen, die blutige Anfänger in Programmierung oder Digital Humanities sind. Bis zum Ende des Buches werden dir all diese Punkte näher gebracht:
- Die Basics der Programmierung
- Verschiedene Methoden der Analyse von schriftlichen Werken
- Sentimental Analysen mit Neuralen Netzwerken
- etc.
Allgemeines Ziel dieses Buches ist es, das Verständnis dafür zu entwickeln, wie wir mit Python Texte analysieren, um wertvolle Erkenntnisse aus großen Textmengen zu extrahieren.
Falls du ein blutiger Anfänger in Python sein solltest, dann lohnt es sich über das Kapitel Grundlagen zu gehen, sonst nutze dieses Buch gerne als Nachschlagewerk und springe zu den Kapitel, die dich interessieren.
Was ist Digital Humanities?
Digital Humanities (DH), oder auch "digitale Geisteswissenschaft" auf Deutsch, ist die Idee moderne digitale Technologien zu benuzten, um im Kontext einer Geisteswissenschaft, wie zum Beispiel der Germanistik, Japanologie, Korea Studie usw., neue Kentnisse über menschliche Werke zu schaffen.
Es ist nicht klar definiert wo DH beginnt und wo es endet. In diesem buch werden wir Python benutzen, um menschliche, textbasierte Werke zu analysieren, aber wir sind nicht gezwungen etwas zu programmieren, damit man es DH nennen kann. Wir könnten auch Photoshop, Blender oder Adobe Premier benutzen. Auch in Kombination mit der Programmierung, um zum Beispiel 3D Modelle von alten Städten zu erstellen, in der der User rumlaufen könnte, um zu zeigen wie Menschen damals gelebt haben.
In vielen DH Projekten werden Programmiersprachen verwendet, weil die Möglichkeiten, was man alles machen kan, schier unendlich sind. Vorallem mit dem Fortschritt in AI und Large Language Modellen (LLM) kann man menschliche Texte nochmal viel besser und effektiver analysieren. Zum Beispiel werden wir im Kapitel: ROBERTA Analysis LLM Modelle aus dem Internet runterladen, um damit die Gefühlslage, zB. von einer Produktrezession zu ermitteln, sprich ob es positiv, negativ oder neutral geschrieben worden ist. Oder Im Kapitel: Word embeddings werde ich zeigen, wie wir eigene Neurale Netzwerk Modelle trainieren, um Ähnlichkeiten von Wörten zu erkennen.
Um einen besseren Eindruck zu bekommen, was alles möglich ist, werde ich dir ein paar DH Projekte vorstellen.
DemiScript
DemiScript ist eine Annotierungssoftware entwickelt von Koray Birenheide, der sein Master in der Japanologie an der Goethe Universität absolvierte, mit dem Ziel damit japanische Werke oder auch Karten zu annotieren. Man kann mit DemiScript auch Touren erstellen, die den User durch das Dokument führen und einem zum jeden Punkt extra Informationen anzeigen kann. Im Grunde genommen wie eine digitale Museumstour.
Emily Dickson Lexicon
Das Emily Dickson Lexicon ist die digitalisierte Version des Webster Lexicons, welches Emily Dickson auf ihren Schreibtisch hatte. Man kann durch alle Gedichte gehen und auf einzelne Wörter klicken, um die Definition von genau dem Lexicon zu bekommen, welches sie damals nutzte, um den Kontext der Wörter zu verstehen, die sie selber damals nutzte.
Und noch viele, viele mehr.
Vielleicht werde ich hier auch eines Tages dein Projekt vorstellen 😃
Was ist Python?
Python ist eine general-purpose language, oder Allzwecksprache auf Deutsch.
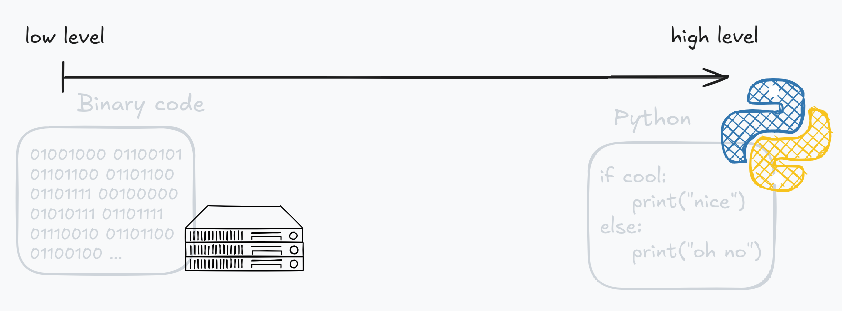
Das heißt wir können Python für so ziemlich alles verwenden. Zudem ist Python auch high level. "High level" kann man auch als "einfach" übersetzen. Programmierer kategorisieren Computersprachen in zwei Kategorieren: "high level" und "low level". "low level" bedeutet, dass etwas sehr nah an der "Maschine" ist. Sprich wenn ich "low level code" schreibe, dann könnte das bedeuten, dass ich mir mehr Gedanken machen muss, über Syscalls (Exekutionen die das Betriebssystem macht) oder ob etwas im "Stack" oder "Heap" vom RAM (Random Access Memory) gespeicher wird. Wenn du gerade nichts verstanden hast, dann ist das vollkommen ok, weil wir Python Code schreiben werden und weil Python "high level" ist, müssen wir nichts von diesen Sachen beachten und können, ohne komplette Computernerds zu sein, Code schreiben!
In anderen Worten: Low level = schwierig und High level = einfach.
Im Laufe des Buches werden wir uns auf Textanalyse, ein Teil von Digtial Humanities, konzentrieren, aber wir können mit Python auch Mobileapps, Videospiele, usw., so ziemlich alles, sogar Webseiten programmieren. Alle Skills, die du in diesem Buch lernen wirst, kannst du somit auch auf andere Bereiche anwenden und somit dein Horizont "ganz einfach" erweiteren und vielleicht sogar eine Karriere aufbauen.
Weil es nicht schaden kann, hier noch ein paar Fakten zu Python von Wikipedia:
- Python wurde 1980 von Guido van Rossum erfunden.
- Python ist Open Source, sprich komplett kostenlos
- Python ist die beliebteste Sprache für Datascience und Machine Learning und dementsprechend auch perfekt für Digital Humanities
Ein großer Vorteil von Python ist, dass der Code sehr an der normalen englischen Sprache erinnert und somit einfach verständlich ist, auch für diejenigen, die noch nie programmiert haben.
# Eine Liste von Zahlen erstellen
numbers = [1, 2, 3, 4, 5]
# Gesamtwert initialisieren
sum = 0
# Schleife durch jede Zahl in der Liste
for number in numbers:
# Hinzufügen der Zahl zur Summe
sum += number
# Ausgabe der Gesamtsumme
print("Die Summe der Zahlen ist:", sum)
In diesem Codebeispiel rechnen wir das Ergebnis aller Zahlen zusammen
und geben das Ergebnis in einer Konsole aus.
Hier ist der Output des Codes:
Die Summe der Zahlen ist: 15
Vielleicht verstehst du nicht alles sofort von diesem Codebeispiel. Darum geht es auch gar nicht. Das werden wir in den nächsten Kapiteln noch lernen. Mit dem Codebeispiel wollte ich dir nur mal zeigen wie leicht verständlich Pythoncode auch für totale Programmieranfänger sein kann.
Dieses Buch ist unter der GNU Free Documentation License Version 1.3, 3 November 2008, veröffentlicht.
Eine Kopie dieser Lizenz findest du im Abschnitt Lizenz dieses Buches.
Inhaltsverzeichnis
Python
Um in Python programmieren zu können, sollte Python auch auf deinem System installiert sein. Glücklicherweise kann man Python so ziemlich auf alles installieren, vorallem auf Windows, macOS oder Linux.
Hier habe ich jeweils Anleitungen für die drei meist vebreiteten Betriebsystemen:
Windows
Downloade den latest Python Installierer für Windows von python.org
und führe die .exe Datei aus.
Momentan gibt es mit ein paar Packages, die wir in späteren Kapitel für die programmatische Textanalyse brauchen, die neurere Version als 3.12 von Python nicht mehr supporten. Dies kann sich jederzeit, von einem Tag zum anderen ändern. Also wenn du Probleme haben solltest, dann probiere Python 3.12 zu installieren!
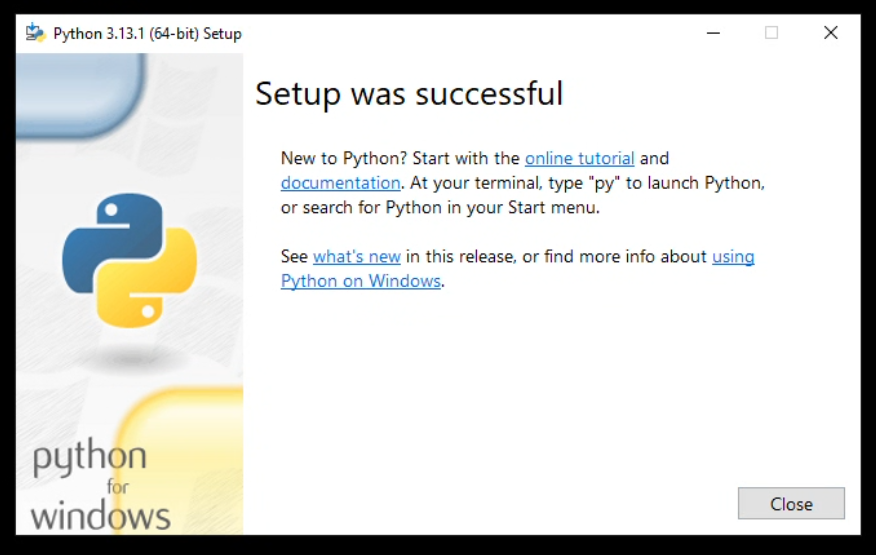
Wenn du die gedownloadete ".exe" Datei ausführst, dann siehst du dieses Fenster:
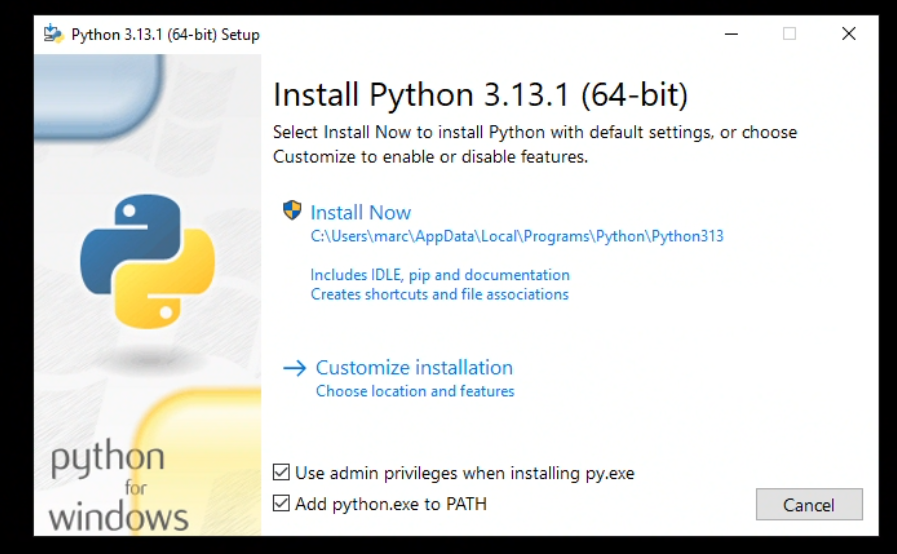
Hier kannst du, so wie ich, einfach alles ankreuzen. Aber gehe sicher, dass "Add python.exe to PATH" angekreuzt ist, damit können wir nach der Installation Python in der "cmd"-Konsole ausführen.
Und das wars auch schon!
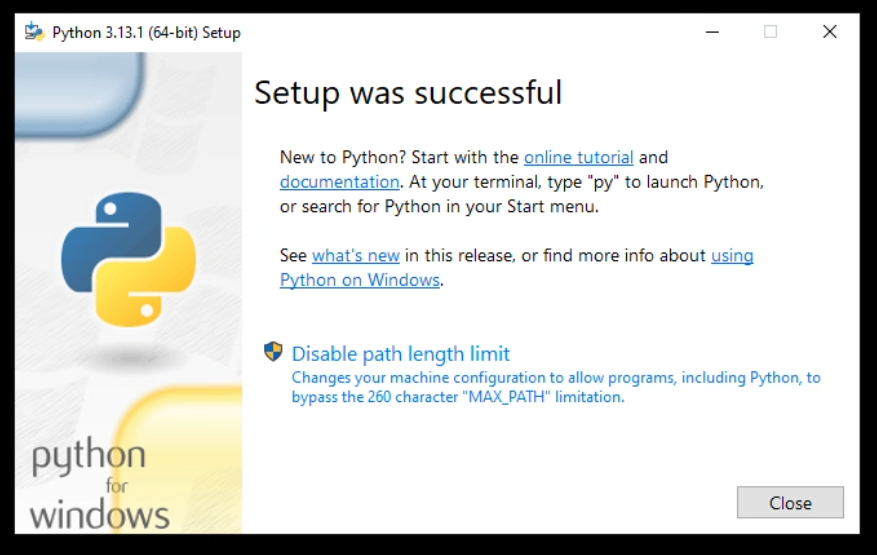
Wenn du "Setup was successfull" siehst, dann hat alles geklappt. Vielleicht siehst du noch im selben Fenster, wie ich hier, einen Text mit "Disable path length limit". Klicke einmal drauf, und die Meldung sollte dann auch von selber verschwinden.
Jetzt öffne "cmd" Konsole und gebe python --version ein. Genauso wie ich hier:
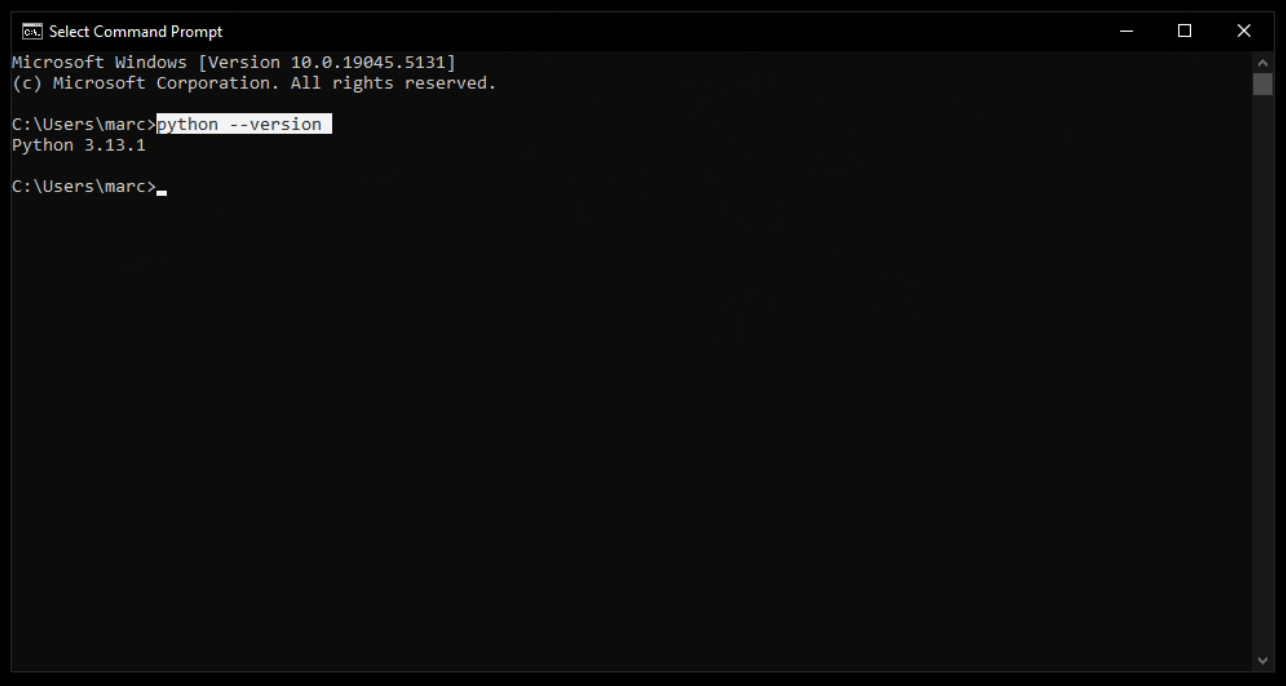
Wenn du Python <irgendeine version> sehen kannst, dann hast auch wirklich alles geklappt.
Alternativ kannst du auch Python schon vom Windows Startmenü öffnen,
aber dies öffnet dann die "REPL". Was das ist werden wir noch lenern!
Jetzt wo Python erfolgreich installiert wurde, können wir im nächsten Kapitel uns darum kümmern einen Texteditor zu installieren.
macOS
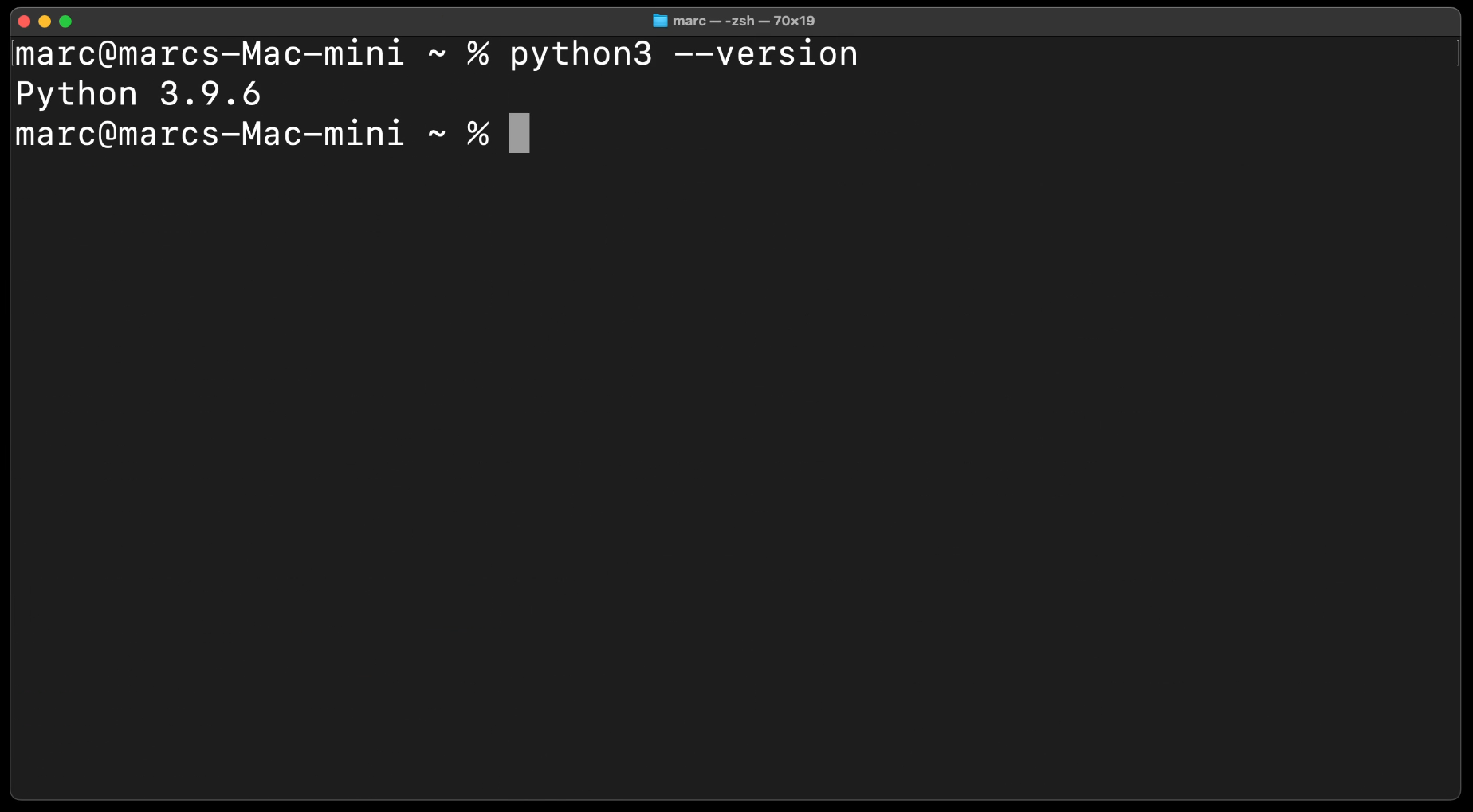
Auf macOS sollte Python schon vorinstalliert sein, also musste hier nichts machen. Um zu schauen, ob es auch wirklich auf deinem Mac installiert ist, gebe diesen Befehl ein:
python3 --version
Um Python Skripte, die wir hier schreiben, auf einen Mac auszuführen,
musst du immer python3 anstelle python eingeben!
Oder du kannst einen "alias" erstellen, dass wenn du immer "python" eingibst, automatisch "python3" ausgeführt wird, dazu musst du nur diesen Befehl hier im Terminal ausführen:
echo 'alias python="python3"' >> ~/.zshrc
homebrew
Aber falls du eine neuerer Version von Python brauchst, dann kannst du diese ganze einfach mit dem "homebrew" Package Manager installieren. Dafür müssen wir erstmal homebrew installieren.
Öffne den Terminal und tippe diesen Befehl in die Konsole:
xcode-select --install
Dies installiert alle "basic tools", die du brauchst fürs Programmieren.
Danach gehe auf die brew.sh Website und kopiere den Befehl unter Install Homebrew.
Der müsste ungefähr so aussehen:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Achtung! Dieser Befehl downloadet ein Installations-skript und führt es auf deinem Computer aus, um homebrew
auf deinen Mac zu installieren. Obwohl es relativ sicher ist,
ist dies theoretisch sehr gefährlich einfach so Skripts zu downloaden und auszuführen.
Also gehe sicher, dass du diesen Befehl von der originalen brew.sh Website kopierst!
Wenn homebrew erfolgreich installiert wurde, siehst du im Terminal die nächsten Schritte, die du machen musst, damit du auch homebrew benutzen kannst. In meinem Fall es drei Befehle:
echo >> /Users/marc/.zprofile
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> /Users/marc/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv)
Achtung! Mein User hier heißt marc und deswegen sind deine drei Befehle wahrscheinlich ein bisschen anders!
Jetzt kannst du im Terminal brew doctor eingeben, um sicher zu gehen, dass alles richtig installiert wurde.
Nun kannst du mit nur einem Befehl Python installieren.
brew install python
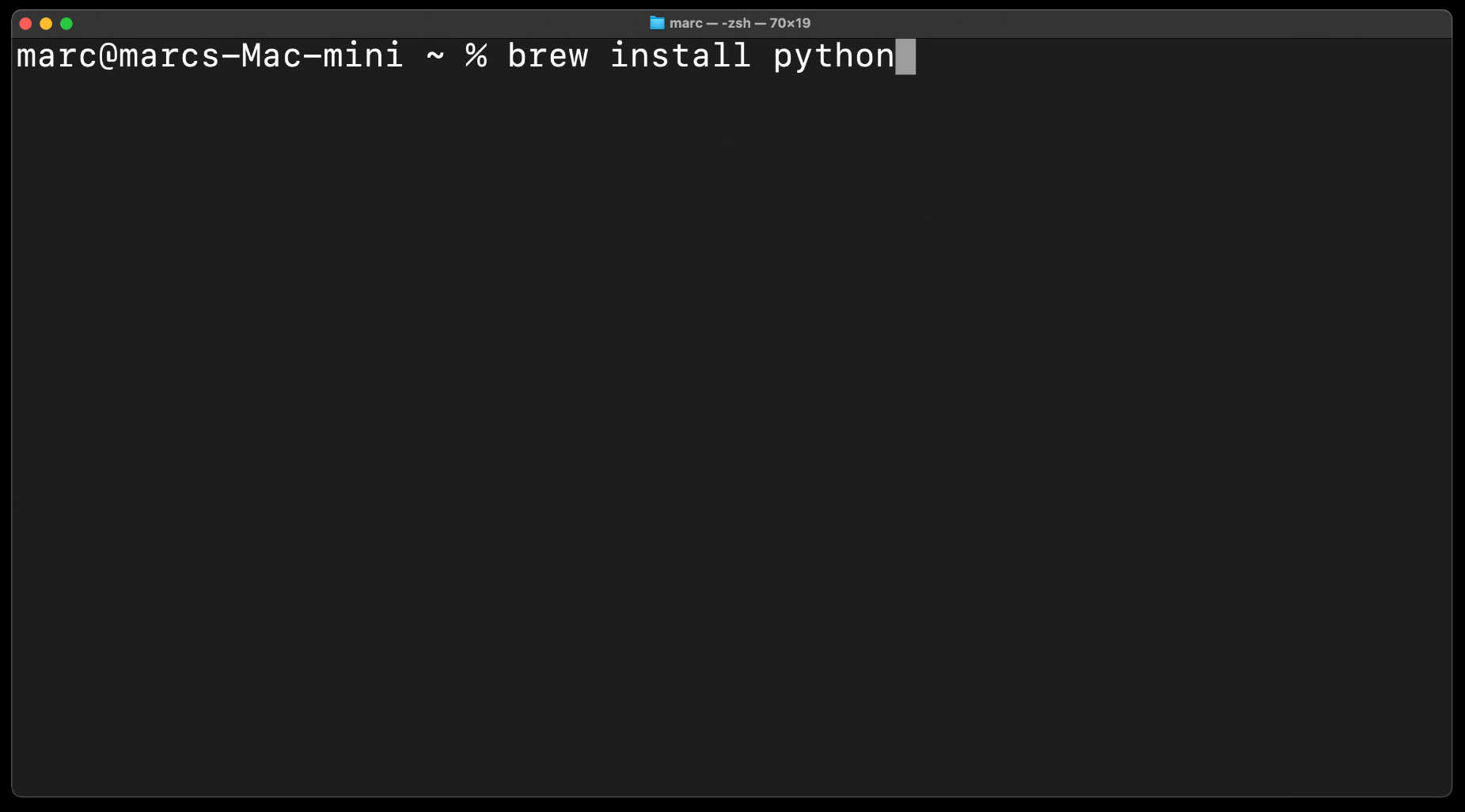
Um sicher zu gehen ob Python auch funktioniert gebe python --version ein,
um die installierte Version von Python ausgespuckt zu bekommen.
Ubuntu
Auf Ubuntu und wahrscheinlich jedem anderen Linux basierten Betriebsystem sollte Python vorinstalliert sein. Wenn nicht, dann kannst du es auf Ubuntu-basierten Systemen mit diesem Befehl hier installieren:
sudo apt install python
Fertig! Zum Testen gebe python --version ein, um zu schauen ob es auch richtig installiert wurde.
Einführung in python
python
Schreibe Code in REPL
exit()
unter macOs und Windows einfach, aber windows?
erstelle main.py mit print("Hello World")
$ python main.py
VScode
Zum besseren Programmieren fehlt uns jetzt nur noch ein Texteditor. Für Anfänger empfehle ich VScode.
Installiere VScode, indem du auf dieser Webseite den richtigen Installer für dein Betriebssystem downloadest und die Installations Datei ausführst.
Einführung in
Öffne VScode
erstelle einen Projektordner
erstelle main.py
installiere python plugin
print("Hello World")
führe die main.py aus
So jetzt müsste alles richtig eingerichtet sein
und wir können uns darauf konzentrieren Python und die Basics der Programmierung zu lernen.
Also Let's go!
Grundlagen
Jetzt können wir anfangen coden zu lernen! Im diesen Kapitel lernen wir die ganzen Basics, die man kennen sollte, bevor wir mit den ersten realen, praktischen Anwendungsbeispiel anfangen: der programmatischen Textanalyse. Aber "gut Ding braucht gut Weile". Fangen wir erstmal mit Variablen an.
Variablen
Variablen, den Begriff kennen wir schon von der Mathematik.
Es bedeutet, dass ein Wert variabel ist, also sich verändern kann.
Zum Beispiel die Variable x in y = x + 2 ist ein Platzhalter für beliebig vielen Werten.
Auch so in der Programmierung sind Variablen als eine Art "Platzhalter" oder viel mehr "Zwischenspeicher" für einen Wert, zu verstehen.
Aber durch Theorie allein kann man nur schwer lernen oder etwas verstehen, also lass uns eine Variable erstellen, die mein jetziges Alter "zwischenspeichert".
my_age = 25
Ich habe hier eine Variable mit den Namen my_age erstellt
(in Programmierfachchinesisch nennt man das auch "deklarieren").
my_age bekommt den Wert 25 zugewiesen.
Um in Python eine Variable zu deklarieren, dürfen wir das = nicht vergessen,
dadurch weiß Python überhaupt erst, dass my_age eine Variable ist.
Ohne das = könnte Python unser Code nicht verstehen und wir würden einen Error bekommen.
Wenn ich jetzt mein Alter wissen möchte
(weil ich es wieder einmal vergessen habe, was mir oft passiert...),
dann kann ich darauf zugreifen, indem
ich in einer späteren Zeile im Skript einfach nur my_age schreibe.
Mit dem print Befehl können wir die my_age Variable in der Konsole ausgeben.
Machen wir das einmal:
my_age = 25
print(my_age)
Wenn wir unser Skript ausfüheren, dann sehen wir folgendes in der Konsole:
25
Überall wo wir jetzt my_age brauchen, können wir,
anstelle immer wieder 25 zu schreiben, my_age schreiben.
Der Vorteil ist, wenn wir unser Code für einen anderen User anpassen möchten,
dann müssen wir nur die Zeile, in der wir my_age deklariert haben, anpassen.
Datentypen
Neben Zahlen können wir auch Variablen für Text, Listen und viele, viele anderen Dinge erstellen.
In diesen Kapitel gehen wir Schritt für Schritt über die wichtigsten Datentypen von Python und wie man mit diesen arbeiten kann.
Hier schonmal eine kleine Übersicht von all den Datentypen, die ich dir näher bringen werde:
| Datentyp | Ein-Wort-Erklärung |
|---|---|
| Number | Zahl |
| Boolean | Wahr oder Falsch |
| String | Text |
| List | Liste an Werten |
| Tuple | Unveränderbarde Liste an Werten |
| Dictionary | Key und Value Liste |
Den Typ einer Variable können wir mit dem type Befehl heraus bekommen.
Zum Beispiel hier einmal der Datentyp von der Variabel my_age, die wir im letzten Kapitel erstellt haben.
print(type(my_age))
<class 'int'>
Mit dem print Befehl um type(my_age) gehe ich auch sicher, dass der Typ in der Konsole ausgespuckt wird.
Number
Einer der wohl wichtigsten und offensichtlichsten Datentypen einer Programmiersprache ist die Nummer oder auch Zahl.
In Python, sowie auch in vielen verschiedenen Programmiersprachen, gibt es zwei verschiedene Arten von Zahlen.
- Integer sind Ganzzahlen, z.B. 420 oder -69 und so weiter...
- Float sind Gleitkommazahlen, z.B. 24.7 oder -4.2069
Beachte: Python benutzt . für die Gleitkommazahlen, wie in der englischen Sprache.
Egal ob integer oder float mit beiden Zahlentypen können wir ganz normal rechnen:
Plus +
x = 5
y = 3.5
z = x + y
print(z)
8.5
Minus -
x = 5
y = 3.5
z = x - y
print(z)
1.5
Mal *
x = 5
y = 3.5
z = x * y
print(z)
17.5
Geteilt /
x = 5
y = 3.5
z = x / y
print(z)
1.4285714285714286
Hoch **
x = 5
y = 3.5
z = x ** y
print(z)
279.5084971874737
Modulus %
Der Modulus % wird verwendet, um den Rest einer Division zu berechnen.
Kannst du dich vielleicht noch erinnern,
wie du in der Grundschule geteilt rechnen gelernt hast und
am Ende der Rechnung den Rest angegeben hast,
z.b. 5 / 2 = 2 Rest 1.
Der Modulus funktioniert genau so, aber dass wir nur den Rest bekommen!
Also 5 % 2 gibt uns die Zahl 1 oder 11 % 3 ergibt 2.
Zum Beispiel können wir den Modulus verwenden,
um zu erkennen ob eine Zahl gerade oder ungerade ist,
denn wenn x % 2 null ergibt, dann ist die Zahl durch zwei teilbar
und wenn es eins ergibt, dann eben offensichtlicher Weise nicht.
print(5 % 2)
print(8 % 2)
1
0
Noch mehr Mathe mit dem math Modul
Falls man aber noch mehr Mathe machen möchte als nur Plus, Minus oder Geteilt, dann lohnt sich ein Blick in das "Math" Modul.
Zu aller erst müssen wir "math" importieren.
Schreibe dafür dies hier ganz oben als erste Zeile in der .py Skript Datei.
import math
math.ceil()
Mit math.ceil() können wir eine Zahl, die wir innerhalb der () Klammern packen, aufrunden.
x = math.ceil(9.3)
print(x)
10
math.floor()
Oder mit math.floor() können wir eine Zahl abrunden:
x = math.floor(9.3)
print(x)
9
math.trunc()
math.trunc() schneidet alles nach der Kommastelle weg, damit wir eine Ganzzahl bekommen.
x = math.trunc(9.3)
print(x)
9
math.exp()
math.exp() gibt uns das Ergebnis von "e hoch x":
x = math.exp(9)
print(x)
8103.083927575384
math.sqrt()
Ziehe die Wurzel von einer Zahl:
x = math.sqrt(9)
print(x)
3.0
math.cos()
Berechne den Kosinus von einer Zahl:
x = math.cos(0)
print(x)
1.0
Noch mehr Information zum "Math" Modul findest du hier.
Übungsaufgaben
Hier ein paar Übungsaufgaben, die du nun lösen kannst, um deine Programmierskills auf die Probe zustellen! 💪
- Berechne die gesamte Anzahl an Tagen anhand des Alters einer Person.
Zeige Lösung
- Berechne wie viele Sekunden X Stunden hat, wo X eine beliebige Zahl ist.
Zeige Lösung
- Ermittle anhand des Geburtsjahres wie alt eine Person ist
Zeige Lösung
- Ermittle den Rest einer Division von zwei Zahlen
Zeige Lösung
- Berechne den Flächeninhalt eines Dreiecks (a: 5cm, b: 5cm, c: 10cm)
Zeige Lösung
Boolean
Den nächsten Datentyp, den wir lernen werden, ist der Boolean.
Ein Boolean kann nur zwei mögliche Werte haben kann:
"wahr" also True oder "falsch" also False.
Stelle dir einen Boolean wie einen Lichtschalter vor,
der entweder ein- oder ausgeschaltet sein kann.
In diesem Fall ist "eingeschaltet" True und "ausgeschaltet" False.
In der Programmierung sind Booleans nützlich, um Entscheidungen zu treffen oder den Ablauf eines Programms zu steuern. Zum Beispiel kann man Booleans verwendet, um zu bestimmen, ob ein Kunde erlaubt ist von einem Onlineshop Alkohol zu kaufen oder ob der User sein Programm in Light oder Dark Theme eingestellt hat.
is_light_theme = True
user_can_buy_alcohol = False
Die bool Funktion
Mit der bool können wir so ziemlich fast alles und auch Variablen zu einem boolean umkonvertieren.
x = 42
x_as_bool = bool(x)
print(x_as_bool)
True
Warum 42 zu True wird, werden wir im nächsten Kapitel lernen!
Logische Operatoren
Logische Operatoren sind spezielle Symbole, die in der Programmierung verwendet werden, um logische Vergleiche zwischen zwei oder mehreren Ausdrücke zu machen.
In anderen, einfacheren Worten: ein Logischer Operator ist wie eine Behauptung, die entweder wahr oder falsch sein kann.
Wenn ich behaupte, dass die Corona Impfung ein Versuch von Bill Gates sei,
die Menschheit zu unterjochen, dann ist die Aussage entweder True oder False. :P
Hier eine Tabelle von allen Logischen Operatoren, die es in Python gibt. Einige sollten dir vom Mathe Unterricht bekannt sein:
| Operator | Bedeutung |
|---|---|
and | und |
or | oder |
== | gleich |
!= | nicht gleich |
not | nicht |
< | kleiner als |
> | größer als |
<= | kleiner gleich |
>= | größer gleich |
Aber keine Sorge, ich gehe über jeden Operator und gebe dir ein Beispiel, wie man es benutzt.
and
print(True and False)
False
Der "und"-Operator überprüft ob die beiden Werte, links und rechts, True sind.
Zum Beispiel wir wollen überprüfen ob ein Kunde, der Alkohol kaufen möchte, über 18 ist und einen Ausweis mit sich trägt. Nur wenn beides der Fall ist, können wir ihm guten Gewissens Alkohol verkaufen:
is_adult = True
has_passport = False
print(is_adult and has_passport)
False
Aber erst wenn ein Kunde unseren Onlineshop besucht und beides erfüllt, können wir endlich Profit mit unserem Alk machen.
is_adult = True
has_passport = True
print(is_adult and has_passport)
True
or
print(True or False)
True
Der "oder"-Operator überprüft ob links oder rechts True ist.
Nur eine der beiden Seiten muss True sein, damit die Aussage als True gilt.
Zum Beispiel in einer Dating App möchte ich mit Personen gematched werden, die entweder Hunde oder Katzen mögen.
likes_cats = True
likes_dogs = False
print(likes_cats or likes_dogs)
True
==
print(True == False)
False
Der "gleich"-Operator überprüft ob die linke Seite identisch mit der rechten Seite ist. Wir können auch Zahlen und alle anderen Datentypen, die wir noch lernen werden, damit vergleichen.
my_age = 25
your_age = 28
print(my_age == your_age)
your_age = 25 ## Überschreibe your_age mit 25
print(my_age == your_age)
False
True
!=
print(True != False)
True
Das selbe wie beim "gleich" können wir auch hier machen, aber umgedreht mit dem "nicht-gleich"-Operator. Dieser checkt ob die linke Seite nicht gleich mit der rechten Seite ist.
my_age = 25
your_age = 28
print(my_age != your_age)
your_age = 25 ## Überschreibe your_age mit 25
print(my_age != your_age)
True
False
not
print(not True)
False
Der "nicht"-Operator tut einen "boolischen" Wert (True oder False) umdrehen.
So wie wir es oben im Beispiel sehen können, wo True mit not zu False umkonvertiert wird.
Schauen wir uns weitere Beispiel des "nicht"-Operator an!
not True ## -> False
not False ## -> True
not 42 ## -> False
not 0 ## -> True
not -42 ## -> False
Du fragst dich jetzt bestimmt warum not 0 True ist und warum not 42 sowie not -42 False ist.
In vielen Programmiersprachen wird die Zahl 0 als False behandelt,
während alle anderen Zahlen (sowohl positive als auch negative) als True behandelt werden.
Nun, da alle anderen Zahlen (außer 0) als True gelten, sind sowohl 42 als auch -42 wahr.
Wenn wir den "nicht"-Operator auf 42 und -42 anwenden, kehren wir ihre Werte um,
daher werden sowohl not 42 als auch not -42 zu False.
Wir können auch sebstverständlich den "nicht"-Operator an Variablen verwenden.
is_r_cool = False
print(not is_r_cool)
True
<
print(42 < 24)
False
Das "kleiner als"-Symbol wird verwendet, um zwei Zahlen miteinander zu vergleichen.
Wenn die Zahl auf der linken Seite des Symbols kleiner ist als die Zahl auf der rechten Seite,
dann ist die Aussage True oder andernfalls False.
>
print(42 > 24)
True
Das selbe auch beim "größer als"-Symbol.
<=
print(42 <= 24)
False
Das "kleiner gleich"-Symbol tut nicht nur True geben, wenn die linke Seite kleiner ist als die rechte,
sondern auch wenn die linke Seite gleich der rechten Seite ist.
print(42 <= 43)
print(42 <= 42)
print(42 <= 41)
True
True
False
>=
print(42 >= 24)
True
Das selbe auch beim "größer gleich"-Symbol.
print(42 >= 43)
print(42 >= 42)
print(42 >= 41)
False
True
True
Im nächsten Kapitel werden wir all diese Operatoren verwenden,
um mit Hilfe von if und else in unserem Programm Entscheidungen treffen
zu können.
if und else
Mit if und else können wir innerhalb unseres Programmes Entscheidungen treffen,
um eine Aktion auszuführen, wenn eine bestimmte Bedingung erfüllt ist
und eine andere Aktion, wenn die Bedingung nicht erfüllt sein sollte.
number = 5
if number % 2 == 0:
print("number is even")
else:
print("number is odd")
Nach dem if-Schlüsselwort folgt ein Aussage, die sich entweder zu True oder False auflöst.
In der nächsten Zeile ist, der Code, der ausgeführt werden soll, wenn die Aussage True ist,
indentiert mit einem Tab.
Wenn aber die Aussage False ist, wird der else Block ausgeführt.
Also nochmal einfacher erklärt mit einem Pseudocode-Beispiel:
if this_is_true:
do_this()
else:
do_that()
Im Beispiel von ganz oben wird "number is even" in der Console ausgegeben, wenn der Rest von number
geteilt durch zwei null ist, also die Zahl gerade ist und wenn dies nicht der Fall ist,
dann wird "number is odd" ausgegeben.
Wir können auch mehrere if's hintereinander reihen um mehrere Bedingungen Schritt für Schritt zu überprüfen.
if this_is_true:
do_x()
elif or_this_is_true:
do_y()
else:
do_z()
elif steht hierbei für else if, oder auch "oder wenn" auf Deutsch.
Lass uns ein Beispiel schreiben, bei dem in der Console eine Nachricht geschrieben wird, wenn die Zahl positiv, negativ oder null ist.
number = -7
if number < 0:
print("Number is negative.")
elif number > 0:
print("Number is positive.")
else:
print("Number is null.")
Als erstes checken wir ob die Zahl kleiner als null ist, dann printen wir "Number is negative" und
wenn die Zahl größer als null ist, dann printen wir "Number is positive".
Wenn beides nicht der Fall ist, also beide Aussagen False sind dann wird der else Block ausgeführt und
logisch können wir ab diesen Punkt ab an davon ausgehen, dass die Zahl 0 sein muss!
Wir sind aber nicht verpflichtet ein else zu verwenden am Ende einer if-Kette.
do_x()
if this_is_true:
do_y()
do_z()
So können wir zum Beispiel erst x machen und wenn die if-Aussage True ist,
dann machen wir auch y, aber wenn es False ist, naja, dann machen wir halt y nicht
und ungeachtet der if Aussage, machen wir z als nächstes.
Übungsaufgaben
Hier ein paar Übungsaufgaben mit if und else.
- Überprüfe, ob eine vom Nutzer eingegebene Zahl positiv, negativ oder null ist.
So kannst du auf eine Eingabe vom Nutzer abwarten und diese zu einem
integerumwandeln:user_input = input("Gebe bitte eine ganze Zahl ein: ") number = int(user_input)
Zeige Lösung
user_input = input("Gebe bitte eine ganze Zahl ein: ")
number = int(user_input)
if number > 0:
print("Zahl ist positiv")
elif number < 0:
print("Zahl ist negativ")
else:
print("Zahl ist null")
- Überprüfe, ob eine vom Nutzer eingegebene Zahl gerade oder ungerade ist.
Zeige Lösung
user_input = input("Gebe bitte eine Zahl ein: ")
number = float(user_input)
if number % 2 == 0:
print("Zahl ist gerade")
else:
print("Zahl ist ungerade")
- Lass den Nutzer zwei Zahlen eingeben und vergleiche diese beiden Zahlen und gib an, welche größer ist.
Zeige Lösung
number_one = float(input("Gebe bitte die erste Zahl ein: "))
number_two = float(input("Gebe bitte die zweite Zahl ein: "))
if number_one > number_two:
print(number_one, "ist groesser als", number_two)
else:
print(number_two, "ist groesser als", number_one)
- Überprüfe, ob eine vom Nutzer eingegebene Zahl in einem bestimmten Bereich liegt (z.B. zwischen 10 und 20).
Zeige Lösung
number = int(input("Gebe bitte eine ganze Zahl ein: "))
if number >= 10 and number <= 20:
print(number, "liegt zwischen 10 und 20")
else:
print(number, "liegt nicht zwischen 10 und 20")
- Lass den Nutzer zwei Zahlen eingeben und schreibe eine Bedingung, die prüft, ob einer der beiden Zahlen durch die andere ohne Rest teilbar ist, also ein ganzzahliges Vielfaches der anderen ist.
Zeige Lösung
number_one = float(input("Gebe bitte die erste Zahl ein: "))
number_two = float(input("Gebe bitte die zweite Zahl ein: "))
if number_one % number_two == 0:
print(number_one, "ist ein Vielfaches von", number_two)
elif number_two % number_one == 0:
print(number_two, "ist ein Vielfaches von", number_one)
else:
print(number_one, "und", number_two, "sind keine Vielfache von sich")
- Lass den Nutzer drei Zahlen eingeben und erkenne welche davon die größte ist und welche davon die kleinste ist
Zeige Lösung
- Lass den Nutzer sein eigenes Alter eingeben und empfehle aufgrund des Alters einen Film.
Zeige Lösung
String
Ein String, auf Deutsch Zeichenkette, ist einfach nur Text...
Damit Python Text auch als string erkennen kann,
müssen wir den Text mit " oder ' einkapseln.
Beispieltext mit ":
name = "Marc"
oder mit ':
name = 'Marc'
aber, wenn wir die " oder ' vergessen, dann bekommen einen Error:
name = Marc
Traceback (most recent call last):
File "/home/marc/main.py", line 1, in <module>
name = Marc
^^^^
NameError: name 'Marc' is not defined
make: *** [Makefile:8: start] Error 1
Python denkt, dass Marc eine Variable ist, aber natürlich gibt es Marc als Variable
nicht, weswegen wir den Error 'Marc' is not defined bekommen.
Ein string kann auch ein Satz sein, ergo Leerzeichen innerhalb der " oder ' sind erlaubt!
name = "Marc Mäurer"
Wie dir vielleicht aufgefallen ist, haben wir die " Syntax auch schon beim print Befehl benutzt.
Wir können auch "multi-line strings" mit drei """ erstellen:
lorem_ipsum = """Lorem ipsum.
Soluta aut quo tempore quisquam corrupti cum velit deserunt.
Sint ea fugiat eaque aut.
Autem ea suscipit voluptas omnis est.
Et sit id sit aperiam aut ut.
Fuga rerum qui consequatur reiciendis.
"""
in
Mit den in Operator kann man schauen ob ein "Substring" in einem "String" ist,
zum Beispiel ob "Hello" in "Hello World" ist.
Sprich "Hello" in "Hello World" ist True
und "Justice" in "Hello World" wäre dementsprechend False.
x = "Hello World"
is_world_in_x = "World" in x
print(is_world_in_x)
True
List
Stell dir eine Liste wie eine stink-normale Einkaufsliste vor. In dieser Liste können viele verschiedene Sachen drinne stehen, wie z.B. "Ketchup" "Tomaten" "Paprika" etc...
Um eine Liste in Python zu erstellen benutzen wir den [] Klammern und
innerhalb der [] Klammer kommen mit einem Komma getrennt alle Werte rein.
einkaufsliste = ["Ketchup", "Tomaten", "Paprika", "Banane"]
print(einkaufsliste)
["Ketchup", "Tomaten", "Paprika", "Banane"]
In einer Liste kann alles rein, Zahlen, Strings, Booleans, komplett egal was. Hier zum ein Beispiel eine Liste an Zahlen:
numbers = [23, 63, 39, 35, 84, 58]
print(numbers)
[23, 63, 39, 35, 84, 58]
Oder hier eine "gemischte" Liste von verschiedenen Datentypen:
numbers = ["Python", True, 42, False, -10]
print(numbers)
["Python", True, 42, False, -10]
Mit der len Funktion können wir herausfinden wie lang eine Liste ist.
Hier zum Beispiel die Länge unserer einkaufsliste
len(einkaufsliste)
4
Indexing
Wenn wir jetzt wissen wollten was an einer bestimmten Stelle in unserer Einkaufsliste steht,
dann brauchen wir die [] Klammern.
Innerhalb der [] Klammern kommt dann die Zahl für welchen Index wir den Wert haben wollen.
Dabei fangen wir bei 0 and zu zählen, sprich 0 ist der erste Wert, 1 ist der zweite und so weiter.
print(einkaufsliste[0])
print(einkaufsliste[1])
print(einkaufsliste[2])
print(einkaufsliste[3])
Ketchup
Tomaten
Paprika
Banane
Mit einer Minuszahl können wir rückwärts der Liste entlang gehen:
print(einkaufsliste[-1])
print(einkaufsliste[-2])
print(einkaufsliste[-3])
print(einkaufsliste[-4])
Banane
Paprika
Tomaten
Ketchup
Strings sind Listen von Characters
Strings in Python sind nichts als Listen aus Buchstaben. Sprich man kann auf jeden einzelnen Buchstaben eines Strings mit dem entsprechenden Index zugreifen.
my_str = "Hello World"
print(my_str[0])
print(my_str[1])
print(my_str[2])
print(my_str[3])
print(my_str[4])
H
e
l
l
o
Oder man kann auch die Länge eines Strings, wie als wäre es eine stink-normale Liste,
mit der len Funktion ermitteln.
print(len(my_str))
11
Tuple
Tuples sind wie Listen, die man nicht verändern kann (in Programmierfachchinesisch nennt man das auch "immutable").
Lass uns verschiedene Tuples erstellen:
number_tuple = (1, 20, 3)
string_tuple = ("marc", "leon", "david")
mixed_tuple = (420, True, -5, "hallo", False)
All diese Tuples sind immutable. Wir können nichts mehr hinzufügen, entfernen oder bearbeiten. Aber sonst ist ein Tuple wie eine Liste, also können wir auf die einzelne Indexe wie gewohnt zugreifen:
a = (1, 20, 3)
print(a[1])
20
Nun wenn wir den Tuple ändern wollen, dann ist das einzige, was wir machen können, ein komplett neuen Tupel zu erstellen, um damit den alten Tupel zu überschreiben. Zum Beispiel so:
a = (1, 20, 3)
a = (1, 2, 3, 4)
print(a)
print(len(a))
(1, 2, 3, 4)
4
Oder wir können ein Tupel mit der list Funktion zu einer Liste konvertieren,
dieser Liste einen weiteren Wert hinzufügen,
diese wieder mit der tuple Funktion zu einem Tupel konvertieren,
um dann damit den alten Tupelwert zu überschreiben.
Aber du merkst auch schon bestimmt selber, dass dies unnötig kompliziert ist.
Ab diesen Punkt sollte man vielleicht eher eine Liste von Anfang an benutzen,
aber für Lernzwecke zeige ich dir hier den Code,
wie man Tupel im nachhinein verändern kann bzw. bearbeiten kann:
a = (1, 2, 3)
a_list = list(a)
a_list.append(4)
a_list[1] = 20
a = tuple(a_list)
print(a)
print(len(a))
(1, 20, 3, 4)
4
Oder hier ähnlicher Code, aber "cleaner":
a = (1, 2, 3)
print(a)
a = (*a, 4)
print(a)
(1, 2, 3)
(1, 2, 3, 4)
* ist der "unpacking"-Operator.
*a ist das selbe wie als würde ich a[0], a[1], a[2], ..., bis zum Ende des Tupels, schreiben.
Apropos den unpacking-Operator kannst du auch mit Listen verwenden!
Dictionary
Dictionaries, oder auch "Dicts" genannt, sind ziemlich cool. Du kannst es dir sprichwörtlich wie ein Wörterbuch vorstellen. In einem Wörterbuch gibt es zu jedem Wort einen Eintrag. Naja in Python wäre ein Wort ein "key" und die Definition zu dem Wort das zugehörige "value". So wie es in einem Wörterbuch mehrer verschiedene Wörter gibt, so kann man in einem Dictionary mehrere verschiedene Keys haben. ABER so wie es in einem Wörterbuch jedes Wort nur einmal gibt, so können wir in einem Dictionary keinen Key zweimal verwenden!
Zum Beispiel lass uns mal einen "Dict" erstellen:
ages = {
"marc": 27,
"leon": 25,
"david": 29,
}
print(ages)
print(type(ages))
print(len(ages))
{'marc': 27, 'leon': 25, 'david': 29}
<class 'dict'>
3
Im Gegensatz zu einem Tupel, ist ein Dict "mutable", heißt veränderbar. Sprich wir können Values von Keys verändern oder neue Keys hinzufügen.
ages["marc"] = 28
ages["rina"] = 22
print(ages)
{'marc': 28, 'leon': 25, 'david': 29, 'rina': 22}
Wenn wir einen Key wieder entfernen wollen, dann machen wir dies mit del:
del ages["rina"]
print(ages)
{'marc': 28, 'leon': 25, 'david': 29}
Schleifen
In so ziemlich jeder Programmiersprache gibt es Schleifen oder auch "Loops" auf Englisch genannt.
Schleifen ermöglichen es dir, bestimmte Aktionen mehrmals wiederholen zu lassen (in Programmierfachchinesisch wird ein solche Wiederholung einer Schleife auch "Iteration" genannt). Dies ist besonders nützlich, wenn du Code hast, der viele Male hintereinander durchgeführt werden soll und du nicht unbedingt 100-mal hintereinander den selben Code copy-pasten willst.
In Python gibt es zwei verschiedene Arten von Schleifen, die für verschiedene Usecases verwendet werden:
for
Die for Schleife gibt es so ziemlich in jeder Programmiersprache.
Kurzgesagt funktioniert sie so: Für die Variable x in einer Sequenz führe Code aus.
In Python-Code sieht es ungefähr so aus:
for x in sequence:
## ...code
Um die for Schleife besser verstehen zu können,
müssen wir uns ein Beispiel anschauen:
for x in range(1, 10):
print(x)
1
2
3
4
5
6
7
8
9
range(1, 10) erstellt uns eine Liste [1, 2, 3, 4, 5, 6, 7, 8, 9].
Japp, bis 9 und nicht bis 10!!
Warum?? Keine Ahnung, es ist einfach so 🤷
x ist die Variable, die jeden Wert innerhalb dieser Liste animmt.
In diesem Beispiel ist x beim ersten mal durchlaufen der Schleife 1
und dann beim zweiten Mal 2 und so weiter bis 9.
x nimmt dabei pro Durchlauf jeden einzelnen Wert der Sequenz von 1 bis 9 an.
Wir sind nicht gezwungen unsere Schleifen-Variable x zu nennen.
Wir können unsere Schleifenvariable so benennen,
wie es gerade am besten zu unserem Code passt.
Für jeden Durchlauf wird der indentierte Code darunter ausgeführt,
deswegen sehen wir in der Konsole 1 bis 9 je in einer Zeile.
Der Code darunter kann so lang sein, wie wir wollen, solange er die gleichte Indentierung hat.
Lass uns zum Beispiel eine for Schleife schreiben,
die von 1-12, für die Monate in einem Jahr, geht und
in die Konsole schreibt, ob es ein Sommer oder Winter Monat ist:
for month in range(1, 13):
if month >= 6:
print("Summer, month", month)
else:
print("Winter, month", month)
Winter, month 1
Winter, month 2
Winter, month 3
Winter, month 4
Winter, month 5
Summer, month 6
Summer, month 7
Summer, month 8
Summer, month 9
Summer, month 10
Summer, month 11
Summer, month 12
continue und break
Innerhalb einer Schleife können wir auch continue und break benutzen.
continue tut jeden weiteren Code, der kommen würde, überspringen und
geht direkt in die nächste Schleifeniteration.
## Schleife von 1 bis 10
for x in range(1, 11):
## Wenn es durch 3 teilbar ist, dann überspringe
if i % 3 == 0:
continue
## Sonst printe die Zahl in der Konsole
print(i)
1
2
4
5
7
8
10
break bricht eine Schleife sofort ab und es wird keine weiter Iteration und kein
weiterer Code der Schleife ausgeführt.
## Schleife von 1 bis 10
for i in range(1, 11):
## Wenn i gleich 5 ist, dann breche die Schleife ab
if i == 5:
break
## Sonst printe die Zahl in der Konsole
print(i)
}
1
2
3
4
fizzbuzz
"fizzbuzz" wohl die berühmteste Programmieraufgabe auf der Welt. Jeder der Programmieren lernt oder studiert, wird früher oder später diese Aufgabe mal gestellt bekommen, denn fizzbuzz ist das perfekte Problem für Programmieranfänger, die Schleifen lernen. Dann lass uns mal anfangen!
Gehe von 1 bis 100
- Wenn eine Zahl ohne Rest durch 3 teilbar ist, dann gebe "fizz" in die Konsole aus
- Wenn eine Zahl ohne Rest durch 5 teilbar ist, dann gebe "buzz" in die Konsole aus
- Sonst gebe die Zahl so wie sie ist in die Konsole aus
Beispielausgabe vom Ergebnis:
1 2 fizz 4 buzz fizz 7 8 ...
Zeige Lösung
for x in range(1, 101):
if x % 3 == 0:
print("fizz")
elif x % 5 == 0:
print("buzz")
else:
print(x)
Jetzt bearbeite dein Code und gebe "fizzbuzz" in die Konsole aus, wenn die Zahl ohne Rest durch 3 und 5 teilbar ist.
Beispielausgabe vom Ergebnis:
1 2 fizz 4 buzz fizz 7 8 fizz buzz 11 fizz 13 14 fizzbuzz 16 ...
Zeige Lösung
for x in range(1, 101):
is_fizz = x % 3 == 0
is_buzz = x % 5 == 0
if is_fizz and is_buzz:
print("fizzbuzz")
elif is_fizz:
print("fizz")
elif is_buzz:
print("buzz")
else:
print(x)
mit Listen
Wir haben schon gelernt, dass range(1, 10) eine Liste [1, 2, 3, 4, 5, 6, 7, 8, 9] erstellt,
über diese sind wir dann drüber geschliefen.
Sprich dieser Coder hier:
for x in range(1, 10):
print(x)
Ist genau das selbe wie:
for x in [1, 2, 3, 4, 5, 6, 7, 8 ,9]:
print(x)
An der Stelle [1, 2, ..., 9] können wir auch irgendeine andere Liste einsetzen oder eine Variable,
die eine Liste in sich trägt.
Hier ein paar Beispiele:
names = ["marc", "leon", "philipp"]
for name in names:
print("Hello", name)
Hello marc
Hello leon
Hello philipp
ages = [27, 18, 14, 58]
for age in ages:
print("Person is", age, "years old")
Person is 27 years old
Person is 18 years old
Person is 14 years old
Person is 58 years old
mit Tuples
Tuples verhalten sich eins-zu-eins genauso wie Listen. Also giblt es keinen Unterschied, wenn es um for-Schleifen geht.
names = ("marc", "leon", "philipp")
for name in names:
print("Hello", name)
Hello marc
Hello leon
Hello philipp
mit Strings
Strings auf Detusch übersetzt, bedeutet Zeichenkette, ergo eine Kette an Schriftzeichen, ergo eine Liste an Schriftzeichen, ergo wir können wie als wäre es eine Liste über jedes einzelne Schriftzeichen drüber schleifen:
for char in "Hello World":
print(char)
H
e
l
l
o
W
o
r
l
d
mit Dictonaries
Wir können auch ohne Problem über ein Dict schleifen. Aber wenn wir dies tun, dann schleifen wir nur über die Keys. Hier ein Biespiel:
ages = {
"marc": 27,
"leon": 25,
"david": 29,
}
for name in ages:
print(name, "is", ages[name], "years old")
marc is 27 years old
leon is 25 years old
david is 29 years old
.values()
Mit der values Funktion bekommen,
wir eine Liste von all den Values in einem Dict.
ages = {
"marc": 27,
"leon": 25,
"david": 29,
}
for age in ages.values():
print("Person is", age, "years old")
Person is 27 years old
Person is 25 years old
Person is 29 years old
.keys()
Mit keys bekommen wir alle Keys von einem Dict als List.
ages = {
"marc": 27,
"leon": 25,
"david": 29,
}
print(ages.keys())
dict_keys(['marc', 'leon', 'david'])
.items()
items ist super, wenn wir Keys und Values gleichzeitig haben wollen.
Vorallem ist dies sehr praktisch bei einer for-Schleife.
ages = {
"marc": 27,
"leon": 25,
"david": 29,
}
print(ages.items())
dict_items([('marc', 27), ('leon', 25), ('david', 29)])
Wie du sehen kannst, haben wir eine Liste an Tuples, über diese wir jetzt schleifen können.
Apropos das "dict_items" kannst du ignorieren, dass ist nur ein "Wrapper", der für uns jetzt unwichtig ist.ages = {
"marc": 27,
"leon": 25,
"david": 29,
}
for entry in ages.items():
print(entry[0], "is", entry[1], "years old")
marc is 27 years old
leon is 25 years old
david is 29 years old
Es geht aber noch viel einfacher, indem wir zwei Schleifenvariablen beim for-Statement definieren. Diese zwei Variablen werden dann den zwei Werten des Tuples innerhalb der Liste in der selben Reihenfolge zugewiesen. Schaue hier:
ages = {
"marc": 27,
"leon": 25,
"david": 29,
}
for name, age in ages.items():
print(name, "is", age, "years old")
marc is 27 years old
leon is 25 years old
david is 29 years old
Übungsaufgaben
- Addiere alle ungeraden Zahlen zwischen 1 und 100 miteinander
Zeige Lösung
print("Hello World")
- Zähle wie oft der Buchstabe "e" in dem String "erdbeere" vorkommmt
Zeige Lösung
print("Hello World")
- Lasse den Nutzer eine Zahl eingeben und berechne deren Fakultät (z. B. 5! = 5·4·3·2·1).
Zeige Lösung
print("Hello World")
- Lasse den Nutzer einen Text eingeben und zähle, wie viele Vokale (a, e, i, o, u) und wie viele Konsonanten darin stehen.
Zeige Lösung
print("Hello World")
- Gegeben ist diese Liste an Zahlen
[12, 48, 32, -12, 905, 174]. Finde daraus das Medium, den kleinsten Wert, das Maximum, den größten Wert, und das Medium, den Durchschnitt.
Zeige Lösung
print("Hello World")
- Lass den Nutzer eine Zahl eingeben und addiere alle Zahlen bis null darauf. Sprich wenn der Nutzer die Zahl 89 eingibt, dann addiere 88, 87, 86 ... bis 0 auf auf die ursprüngliche Zahl.
Zeige Lösung
print("Hello World")
- Tannenbaum
Zeige Lösung
print("Hello World")
while
while <Statement>:
...
<code>
...
Eine while-Schleife wiederholt sich die ganze Zeit, solange das Statement True ist. Sobald das Statement False wird, wird die Schleife beendet.
Lass es mich mal anhand eines Beispiels erklären:
x = 0
while x < 10:
print(x)
x += 1
0
1
2
3
4
5
6
7
8
9
Zu Beginn definieren wir die Variable x mit 0,
dann started auch schon die while-Schleife.
Diese führt den indentieren Codeblock solange aus bis das Statement x < 10 False wird.
Sprich im ersten Durchlauf, wo x immer noch 0 ist, wird kontrolliert,
ob "x < 10" True ist, wenn ja, dann führe den Code der Schleife aus.
In dem Schleifencode addieren wir eins zu x.
Apropos x +=1 ist das selbe wie x = x + 1.
Im zweiten Durchlauf ist x 1 und deswegen ist x > 10 immer noch true,
solange bis dies nicht mehr der Fall ist.
Sobald x 10 wird, ist das Statement x > 10 False geworden und die while-Schleife wird beendet.
Zum Beispiel, wenn wir das x += 1 vergessen hätten,
dann wird unsere while-Schleife nie enden und dann hätten wir eine sogenannte "Endlosschleife",
welche ich gleich genauer thematisieren werde.
continue und break
Auch bie einer while-Schleife können wir,
genauso wie bei einer for-Schleife, continue und break verwenden.
x = 0
while x < 20:
if x == 15:
break
if x % 2 == 0:
x += 1
continue
print(x)
x += 1
1
3
5
7
9
11
13
Endlosschleifen
Eine Endlosschleife oder auch "infinite loop" und "endless loop" auf Englisch genannt, sind while-Schleifen, die nie enden... 🤯
Ich weiß, hättest du jetzt nicht gedacht, oder?
Zum Beispiel hier eine Endlosschleife:
while True:
print("are we there yet?")
print("no!")
are we there yet?
no!
are we there yet?
no!
are we there yet?
no!
are we there yet?
no!
are we there yet?
no!
are we there yet?
no!
...
Das Statement dieser while-Schleife ist True und naja das ist immer True... offensichtlich, oder?
Apropos mit STR+C kannst du ein Programm in der Konsole oder CMD zum Beenden zwingen. 😉
Aber warum braucht man soetwas? Wir könnten eine Endlosschleife verwenden, um zum Beispiel nach dem Passwort eines Benutzers zu fragen und wenn wir ein falsches bekommen, dann fragen wir solange bis wir das richtige Passwort bekommen.
Du fragst dich jetzt bestimmt: "Eine Endlosschleife ist doch endlos? Wir können wir diese dann beenden, sobald wir das richtige Passwort bekommen haben?" Gute Frage! Vielen Dank.
In einer while-Schleife können wir break benutzen um diese,
egal ob das Statement True oder False ist, zu beenden.
Dementsprechend hier der Code für dieses Beispiel:
correct_password = "1234secret"
while True:
password = input("Try to enter the correct password: ")
if password == correct_password:
print("Login successfull!")
break
else:
print("Wrong password. Please try again.")
Exkursion: Ratespiel
So genug Basics und Theorie gelernt. Lass mal ein kleines Spiel mit unseren neugewonnenen Wissen basteln!
Ich denke hier an ein Ratespiel,
wo der Spieler eine zufällige Zahl erraten muss,
um zu gewinnen.
Python kommt automatisch mit dem "random" Package mitgeliefert.
Von dem random Package benutzten wir die randint Funktion,
um eine zufällige Zahl zu generieren.
from random import randint
x = randint(1, 100)
Hier importiere ich randint vom random Package. Der randint gebe ich zwei Zahlen. Diese zwei Zahlen bestimmen den Bereich von dem ich zufällig eine Zahl haben möchte. Sprich hier bekomme ich zufällig eine Zahl zwischen 1 und 100.
Als nächstes möchte ich den Spieler eine Zahl eintippen lassen.
Dies geht ganz einfach mit der input Funktion.
guess = int(input("📝 ️Errate die richtige Zahl: "))
Die input Funktion lässt den Spieler einen Text eingeben.
lDie Usereingabe wird uns dann mitgeteilt,
sobald der User die Eingabetaste (Enter) gedrückt hat.
Da der Spieler alles eingeben kann, nicht nur Zahlen,
bekommen wir die Usereingaben als ein String.
Diesen String konvertieren wir mit der int Funktion zu einem Integer (ganze Zahl) und speichern diesen in die Variable guess.
Jetzt können wir checken ob der Rateversuch richtig ist und je nachmdem printen wir eine Nachricht in die Konsole.
if guess == x:
print("🎉 Hurrah du hast die richtige Zahl erraten!!!")
else:
print("❌ Leider falsch versuche es nochmal")
Ein Problem. Wenn du dieses Spiel schon einmal ausgeführt hast, dann weißt du wahrscheinlich schon was das Problem ist. Wenn wir die Zahl nicht erraten konnten, wird unser Spiel sofort beendet ohne uns die Möglichkeit zu geben, nochmal die richtige Zahl zu erraten.
Lass daür eine while Schleife nehmen,
die immer wieder den Spieler nach der richtige Zahl fragt,
solange bis sie erraten worden ist.
Außerdem lass Tipps in die Konsole printen,
um den Spieler bei einem missgeglückten Rateversuch zu sagen,
ob seine Zahl drunter oder drüber der richtige Zahl liegt.
from random import randint
x = randint(1, 100)
while True:
guess = int(input("📝 ️Errate die richtige Zahl: "))
if guess == x:
print("🎉 Hurrah du hast die richtige Zahl erraten!!!")
break
else:
print("❌ Leider falsch versuche es nochmal")
if guess > x:
print("Die zu erratende Zahl ist kleiner als", guess)
else:
print("Die zu erratende Zahl ist groesser als", guess)
Sobal wir die Zahl richtig erraten haben, also guess == x,
"breaken" wir aus der while Schleife und somit ist unser Spiel beendet
Natürlich bevor wir das tun, printen wir eine Gewinnnachricht in die Konsole,
sodass der Spieler auch weiß,
dass er gewonnen hat und dass das Programm nicht abgestürzt ist.
Unser Spiel läuft jetzt, aber für immer, solange der Spieler gewinnt. Das ist ziemlich langweilig oder nicht? Lass Leben definieren und bei jeden Fehlversuch ziehen wir ein Leben davon ab und sobald alle Leben weg sind, ist es Game Over.
from random import randint
x = randint(1, 100)
lives = 5
while True:
guess = int(input("📝 ️Errate die richtige Zahl: "))
if guess == x:
print("🎉 Hurrah du hast die richtige Zahl erraten!!!")
break
else:
lives -= 1
print("❌ Leider falsch versuche es nochmal")
if guess > x:
print("Die zu erratende Zahl ist kleiner als", guess)
else:
print("Die zu erratende Zahl ist groesser als", guess)
if lives == 0:
print("💀💀💀 Game Over 💀💀💀")
print("Die richtige Zahl ist: ", x)
break
Am Anfang habe ich die lives Variable erstellt
und nach jedem Fehlversuch ziehe ich mit lives -= 1 eins von lives ab und update den alten Wert von lives.
Sprich lives -= 1 ist das selbe wie lives = lives - 1.
Und am Ende darf natürlich auch kein Game Over Screen fehlen.
Cool, aber der Spieler weiß noch nicht, wie viel Leben er noch übrig hat. Lass dafür eine Lebensanzeige (Healthbar) in die Konsole ausgeben.
from random import randint
x = randint(1, 100)
lives = 5
while True:
### Printing health bar
for _ in range(0, lives):
print("💚️", end=" ")
print("")
guess = int(input("📝 ️Errate die richtige Zahl: "))
if guess == x:
print("🎉 Hurrah du hast die richtige Zahl erraten!!!")
break
else:
lives -= 1
print("❌ Leider falsch versuche es nochmal")
if guess > x:
print("Die zu erratende Zahl ist kleiner als", guess)
else:
print("Die zu erratende Zahl ist groesser als", guess)
if lives == 0:
print("💀💀💀 Game Over 💀💀💀")
print("Die richtige Zahl ist: ", x)
break
Hier printe ich alle Herzen mit am Ende einen leeren String.
In Python wird am Ende eines print Befehls immer ein Zeilenumbruch eingesetzt.
Da ich aber alle Herzen in einer Reige haben möchte,
überschreibe ich diesen Zeilenumbruch mit einem leeren String
und nach der forSchleife,
also sobald alle Herzen gemalt worden sind,
dann printe ich eine leeren String,
aber wenn du genau hinschaust,
dann kannst du sehen,
dass ich jetzt einen Zeilenumbruch mit printe,
damit was auch immer danach an Text noch kommen sollte,
in seiner eigenen Zeile stehen kann.
Und jetzt können wir anfangen zu spielen!
💚 💚 💚 💚 💚
📝 ️Errate die richtige Zahl: 50
❌ Leider falsch versuche es nochmal
Die zu erratende Zahl ist kleiner als 50
💚 💚 💚 💚
📝 ️Errate die richtige Zahl: 25
❌ Leider falsch versuche es nochmal
Die zu erratende Zahl ist kleiner als 25
💚 💚 💚
📝 ️Errate die richtige Zahl: 15
❌ Leider falsch versuche es nochmal
Die zu erratende Zahl ist kleiner als 15
💚 💚
📝 ️Errate die richtige Zahl: 10
🎉 Hurrah du hast die richtige Zahl erraten!!!
Cool oder nicht? Vielleicht hast ja noch andere text-basierte Spielideen. Probiere es ruhig aus. Studieren geht über probieren. Dieses Buch geht zwar über Digital Humanities, aber vielleicht wirst du der nächste Spieleentwickler 😉
Funktionen
Funktionen sind wieder verwendbare Blöcke an Code, die du jederzeit nach Belieben oft ausführen kannst.
Wir haben bis jetzt schon sehr viele Funktionen von Python benutzt.
Zum Beispiel die print Funktion, die eine Zeile in die Konsole ausgibt.
Hier ein Beispiel einer Funktion, die "hello world" in die Konsole ausgibt:
def hello():
print("hello world")
hello()
hello world
Natürlich ist diese Funktion ziemlich sinnbefreit. Im nächsten Kapitel zeige ich dir Schritt für Schritt, wie wir eigene komplexe Funktionen schreiben können, um damit unseren Code besser in logische, wiederbenutzbare Blöcke einzuteilen.
Eigene Funktionen schreiben
def hello():
print("hello marc")
hello()
hello marc
Mit def können wir eine komplett neue Funktion definieren.
Nach dem "def" kommt der Name der Funktion.
Du kannst dich für egal welchen Namen auch immer entscheiden.
Vergesse die () Klammern nicht direkt nach dem Namen der Funktion.
Diese sind nicht nur notwendig, damit wir keinen "SyntaxError" bekommen,
sondern sie haben auch eine Zweck, auf den wir noch später zurück kommen werden.
Der indentierte Block and Code ist der Körper unserer Funktion. Dieser wird immer ausgeführt, wenn wir die Funktion aufrufen.
Wie du in der letzten Zeile sehen kannst,
führen wir unsere Funktion mit den selben Namen und den () Klammern aus
und deswegen sehen wir dann auch "hello marc" in der Konsole.
Probiere es einmal selber aus!
Ok soweit so gut, aber was wenn wir mehrere Leute begrüßen wollen, dann müssten wir entweder unsere Funktion erweitern oder mehrere verschiedene Funktionen schreiben. Zum Beispiel so:
def hello_marc():
print("hello marc")
def hello_leon():
print("hello leon")
hello_marc()
hello_leon()
hello marc
hello leon
Das ist aber zu viel copy-paste, meiner Meinung nach.
Wir können innerhalb der () Klammern auch Variablen definieren,
sogenannte Funktionsparameter, um bei jedem Aufruf,
einen anderen Namen unserer "hello" Funktion zu übermitteln.
def hello(name):
print("hello", name)
hello("marc")
hello("leon")
hello marc
hello leon
Jedoch wenn wir jezte beim Aufrufen unserer Funktion vergessen einen Namen in die () Klammern einzugeben,
dann bekommen wir einen Error!
hello()
Traceback (most recent call last):
File "/home/marc/main.py", line 1, in <module>
hello()
~~~~~^^
TypeError: hello() missing 1 required positional argument: 'name'
Wie man am Error schon erkennen kann, fehlt der "argument" "name", beim Aufrufen der "hello" Funktion. Diesen Error können wir beheben, indem wir für "name" einen "default" definieren. Lass uns diesen mal schnell definieren:
def hello(name = "stranger"):
print("hello", name)
hello("marc")
hello("leon")
hello()
hello marc
hello leon
hello stranger
Schon viel viel besser, aber was wenn wir auch noch die Begrüßung für ein paar Personen anpassen wollen? Lass uns dafür ein zweiten "greeting" Funktionsparameter mit einem Defaultwert definieren, sodass wir deisen bei belieben überschreiben können, wenn wir die "hello" Funktion aufrufen.
def hello(greeting = "hello", name = "stranger"):
print(greeting, name)
hello("hi", "marc")
hello(name = "leon")
hello("what's up")
hi marc
hello leon
what's up stranger
Unsere "hello" Funktion ist jetzt fertig geschrieben.
In Python haben wir viele verschiedene Arten diese aufzurufen, wie du es schon am vorherigen Beispiel vielleicht erkennen konntest.
Wir können die Werte in der Reihenfolge der Parameter übergeben. Sprich der erste Wert wird zum ersten Funktionsparameter von "hello" weiter gegeben und der zweite zum zweiten der Funktion:
hello("hi", "marc")
hi marc
Statt sich auf die Reihenfolge zu verlassen, kannst du auch die Parameter explizit benennen:
hello(greeting = "hi", name = "marc")
hello(name = "marc", greeting = "hi")
hi marc
hi marc
Oder du kannst auch mischen und machen was auch immer du willst:
hello("hi", name = "marc")
hi marc
Private und globale Variablen
Bis jetzt war unsere "hello" Funktion sehr simpel und überschaubar. Wir können aber innerhalb des Funktionskörpers so viel Code reinschreiben wie wir wollen. Wir können while und for Schleifen darin ausführen oder auch Variablen erstellen. Aber alle Variablen, die wir innerhalb der Funktion erstellen, existieren nur innerhalb des Kontextes der Funktion. Man könnte diese Art von Variablen auch "private Variablen" nennen und alle die wir einfach so außerhalb der Funktion erstellen, wären dann "globale Variablen".
Hier ein Biespiel was ich genau meine:
global_var = "im global!!"
def my_func():
private_var = "im private!! and only exist inside this function"
Da "global_var" im keinen Codeblock sondern ganz normal in unserer Scriptdatei erstellt worden ist, ist sie global überall verfügbar und wir könnten innerhalb der "my_func" Funktion darauf zugreifen.
Die "private_var" hingegen, existiert nur innerhalb des Funktionskörpers und würden wir außerhalb der Funktion darauf zugreifen, dann bekommen wir einen Error.
Hier nochmal ein anderes Beispiel mit unserer "hello" Funktion:
def hello():
text = "hello world"
print(text)
hello()
print(text)
hello world
Traceback (most recent call last):
File "/home/marc/main.py", line 6, in <module>
print(text)
^^^^
NameError: name 'text' is not defined. Did you mean: 'next'?
Wie du am Output erkennen kannst wird "hello" erst volkommen ohne Probleme ausgeführt.
Erst die Zeile mit print(text) schmeißt einen Error,
weil Python text nur im Kontext der Funktion kennt nicht global,
so wie wir es hier versuchen.
Natürlich würde unser Script wieder funktionieren, wenn wir "text" einmal global erstellen würden. Und zwar so:
text = "hello global"
def hello():
text = "hello world"
print(text)
hello()
print(text)
hello world
hello global
Obwohl wir zwei Variablen namens "text" haben, sind beide voneinander getrennt und innerhalb der Funktion kennen wir nur "text" mit dem Wert "hello world", doch sobald wir außerhalb des Kontextes der Funktion sind, kennen wir ausschließlich "text" mit dem Wert "hello global".
Was wenn ich jetzt die Variable "text" innerhalb der Funktion wieder entferne, würde dann unser Script noch funktionieren? Lass uns das mal ausprobieren!
text = "hello global"
def hello():
print(text)
hello()
hello global
Wie du siehst, ja! Also vom Kontext der Funktion aus, können wir auf globale Variablen zugreifen, aber nicht anders herum.
return
Funktionen können auch auch etwas zurückgeben, aber was bedeutet das überhaupt?
Stell dir eine Funktion als ein Helfer vor. Wenn Du eine Funktion aufrufst, dann schickst Du den Helfer los, um eine Aufgabe zu erledigen. Bis jetzt haben wir den Helfer immer nur los geschickt und gegebenfalls in die Konsole schreiben lassen. Nun kann man aber jetzt den Helfer los schicken und auf ihn warten bis er etwas zurück bringt.
Für das "Zurückbringen" benutzen wir return
def do_stuff():
do_something()
return some_value
Vorher sahen unsere Funktionen in etwa so aus:
def do_stuff():
do_something()
print_something_to_console()
Zum Beispiel hier eine add Funktion, die zwei Werte nimmt, miteinander addiert und
in die Konsole ausgibt:
def add(a, b):
print("a + b =", a + b)
add(5, 3)
"a + b = 8"
Aber wenn wir mit dem Ergebnis von add(5, 3) weiter rechnen wollen,
dann funktioniert dies nicht, weil unsere add Funktion,
nicht das Ergebnis zurückgibt, sondern es lediglich in die Konsole ausgibt.
Mit return a + b innerhalb des Funktionskörpers können wir das Ergebnis von a + b,
wo auch immer die Funktion aufgerufen wird, zurückgeben, um damit weiterarbeiten zu können.
Lass zum Beispiel das Ergebnis von add mal 10 nehmen:
def add(a, b):
return a + b
x = add(5, 3) * 10
print(x)
80
Unsere add Funktion tut jetzt das Ergebnis von a + b zurückgeben,
dass bedeutet, dass das add(5, 3) von der Zeile, wo wir x deklarieren,
evaluiert und mit dem Ergebnis ausgetauscht wird.
Sprich Python macht aus x = add(5, 3) * 10 => x = 8 * 10.
return als Exitpoint
return dient ist auch ein Exitpoint einer Funktion.
Sobald unsere Funktion eine Zeile erreicht hat die "return" in sich hat,
werden alle folgenden Zeilen danach nicht mehr ausgeführt:
def can_drive(age):
if (age < 18):
return False
else:
return True
print("This line will never be executed!")
print(can_drive(15))
print(can_drive(29))
False
True
return richtig zu verwenden, können deine Skills als Programmieranfänger verzehnfachen.
Also wenn du es nicht auf Anhieb alles verstanden hast,
sei nicht demotiviert.
Manche Dinge brauchen einfach länger zum Verstehen.
Les dir dieses Kapitel nochmal in Ruhe durch oder schau Youtube Videos,
die genau dieses Thema versuchen zu erklären.
Vetrau mir es wird sich für dich lohnen.
*args und **kwargs
Neber den ganz normalen Funktionsparameter, die wir bis jetzt gelernt haben, gibt es auch noch ganz besondere Funktionsparameter, die wir in diesen Kapitel uns mal genauer anschauen werden.
Programmieren wir mal eine einfache sum Funktion,
die mehrere Zahlen miteinander addiert.
def sum(a, b):
return a + b
Wenn wir jetzt aber drei oder mehr Zahlen miteinander addieren wollen, dann müssen wir eben genau so viele Parameter der Funktionsdefinition hinzufügen wie die Anzahl der Zahlen, die wir addieren wollen.
def sum(a, b, c, d):
return a + b + c + d
Jetzt haben wir nur ein Problem... Was wenn ich nur zwei Zahlen miteinander addieren möchte? Dann kann ich entweder eine neue Funktion definieren oder ich gebe jedem Parameter einen Defaultwert von 0.
def sum(a, b, c = 0, d = 0):
return a + b + c + d
Das funktioniert zwar wunderbar, aber das ist nicht sehr elegant... Wir können Python sagen, dass er alle Parameter in einer Liste zusammenfassen soll.
def sum(*args):
res = 0
for arg in args:
res += arg
return res
sum(5, 15, 4)
24
*args ist eine Liste von allen Parametern,
wie du am Output von sum(5, 15, 4) erkennen kannst.
Dabei ist args der Name des Listenparameters.
Der Name ist aber egal.
Wir hätten es auch numbers nennen können.
Das * ist entscheident hier,
um zwischen einen normalen Parametern und Listenparametern zu unterscheiden.
Wir können aber auch normale Parameter mit den * Parameter gleichzeitig verwenden.
def sum(a, b, *args)
res = a + b
for arg in args:
res += arg
return res
**kwargs
Nebe einem * Parameter gibt es auch noch einen ** Parameter,
der ein Dictionary aus allen benannten Parameter macht ("named parameters" auf Englisch).
Hier zum Beispiel eine shopping_list Funktion,
die alle benannte Parameter und ihren Wert in die Konsole ausgibt.
def shopping_list(**kwargs):
for keyword, arg in kwargs.items():
print(keyword, ":", arg, "mal")
shopping_list(tomaten = 5, zwiebel = 3, milch = 1, kichererbsen = 1)
tomaten : 5 mal
zwiebel : 3 mal
milch : 1 mal
kichererbsen : 1 mal
Hier nich eine simple Funktion mit allen drei Funktionsparametertypen kombiniert.
def my_func(normal_arg, *args, **kwargs):
print("Stinknormaler Funktionsparameter:", normal_arg)
for arg in args:
print("Funktionsparameter als Liste:", arg)
for keyword, arg in kwargs.items():
print("Funktionsparameter als Dictionary:", keyword, arg)
my_func("normal", 1, 2, 3, name = "Marc", greeting = "Hi")
Stinknormaler Funktionsparameter: normal
Funktionsparameter als Liste: 1
Funktionsparameter als Liste: 2
Funktionsparameter als Liste: 3
Funktionsparameter als Dictionary: name Marc
Funktionsparameter als Dictionary: greeting Hi
Übungsaufgaben
Um den Sinn von Funktionen und deren Anwendungsgebiet besser zu verstehen, habe ich hier ein paar Übungsaufgaben für dich. Stets nach dem Motto "Studieren geht über probieren" 😉
- Schreibe eine Funktion mit dem Namen "add", die zwei Zahlen als Eingabe bekommt. Die Funktion soll die beiden Zahlen addieren und das Ergebnis zurückgeben.
Beispiel: Wenn du 5 und 6 übergibst, soll die Funktion 11 zurückgeben.
Zeige Lösung
def add(a, b):
return a + b
x = add(5, 6)
print(x)
11
- Schreibe eine "evens" Funktion, die eine Liste mit Zahlen bekommt. Die Funktion soll nur die geraden Zahlen aus dieser Liste nehmen und eine neue Liste mit diesen geraden Zahlen zurückgeben.
Sprich wir geben der Funktion diese Liste
[1, 2, 3, 4, 5, 6]und zurück bekommen wir[2, 4, 6]
Zeige Lösung
numbers = range(1, 101)
def evens(numbers):
even_numbers = []
for number in numbers:
if number % 2 == 0:
even_numbers.append(number)
return even_numbers
print(evens(numbers))
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100]
- Schreibe eine Funktion, die zwei Dinge als Eingabe bekommt:
- einen Text (String) und
- eine Zahl.
Die Funktion soll den Text so oft wiederholen, wie es die Zahl angibt, und das Ergebnis als einen einzigen String zurückgeben.
Beispiel: Wenn der Text "yes" ist und die Zahl 5, soll die Funktion diesen Text fünfmal hintereinander aneinanderreihen: "yesyesyesyesyes"
Zeige Lösung
def repeat_str(text, repeat):
end_string = ""
for _ in range(repeat):
end_string += text
return end_string
print(repeat("yes", 5))
yesyesyesyesyes
- Schreibe eine Funktion, die eine Temperatur in Celsius als Eingabe bekommt und sie in Fahrenheit umrechnet.
Verwende dafür die folgende Umrechnungsformel:
- Fahrenheit = (Celsius × 1.8) + 32
Die Funktion soll das Ergebnis zurückgeben.
Beispiel: Wenn du 25 als Celsius-Temperatur übergibst, soll die Funktion 77.0 zurückgeben.
Zeige Lösung
def fahrenheit(celsius):
f = (celsius * 1.8) + 32
return f
print(fahrenheit(25))
77.0
- Schreibe eine "min_max" Funktion, die eine Liste mit Zahlen bekommt und sowohl das kleinste als auch das größte Element aus dieser Liste zurückgibt.
Die Funktion soll das Ergebnis als Liste mit zwei Werten zurückgeben:
- zuerst das Minimum,
- dann das Maximum.
Beispiel: Bei der Liste [234, 789, 23487, 1] soll die "min_max" Funktion [1, 23487] zurückgeben.
Zeige Lösung
numbers = [234, 789, 23487, 1]
def min_max(numbers):
min = numbers[0]
max = numbers[0]
for number in numbers:
if number < min:
min = number
if number > max:
max = number
return [min, max]
print(min_max(numbers))
[1, 23487]
List comprehension
List Comprehensions benutzt man, um aus Listen neue Listen zu erzeugen. Die allgemeine Syntax lautet:
Zum Beispiel wir haben diese Liste hier:
numbers = [1, 2, 3, 4, 5]
Und ich möchte alle diese Zahlen quadrieren, dann kann ich es so aus numbers eine quadrierte Liste machen:
bigger_numbers = [num ** 2 for num in numbers]
for num in numbers kennen wir schon von der for Schleife
und heißt "schleife über alle Zahlen von numbers".
num ist dann die Iterationsvariable mit der jetzt was machen können
und was wir machen, steht ganz am Anfang num ** 2.
All das umschachteln wir mit [] Klammern,
weil wir ja eine neue Liste haben wollen.
print(bigger_numbers) gibt uns dann das hier:
[1, 4, 9, 16, 25]
Eine Liste filtern
Nicht nur können wir so eine Liste verändern,
sondern wir können mit einer ähnlichen Syntax auch eine Liste filtern.
Lass zum Beispiel von numbers alle ungeraden Zahlen entfernen!
evens = [num for num in numbers if num % 2 == 0]
print(evens)
[2, 4]
Was passiert hier?
- Mit
for num in numbersgehen wir über alle Zahlen vonnumbers. - Mit
if num % 2 == 0am Ende drückt aus, dass wir die Zahl behalten wollen, die Behauptung vonnum % 2 == 0nach demifTrueist. Wenn nicht dann wird, dann ignorieren wir diesenum. - Die
numam Anfang sagt, dass wirnumso wie es ist zur Liste hinzufügen, aber auch nur wenn dasifTrueist.
Eine Liste filtern und verändern
Wir können auch nach geraden Zahlen filtern und gleichzeitg eine List hoch zwei nehmen.
bigger_and_evens = [num ** 2 for num in numbers if num % 2 == 0]
print(bigger_and_evens)
[4, 16]
match
match ist wie if aber auf Steroide.
Mit einem match Statement können wir je nach dem Wert einer Variable beliebig viel Fälle (case) definieren.
Zum Beispiel hier dieses match Statement führt je nach dem Wert von x Code aus
match x:
case 10:
print("x is ten")
case 20:
print("x is twenty")
case _:
print("default case. i dont know")
Wir könnten auch ganz viele if-else Statments hintereinander benutzen, aber match ist einfacher zu lesen und dementsprechend macht es unser Code einfacher nachzuvollziehen. Lass uns einmal match Code zu if-else migrieren:
if x == 10:
print("x is ten")
elif x == 20:
print("x is twenty")
else:
print("default case. i dont know")
Ja. Matches sind einfach nur eine neue Form if-else zu schreiben,
aber wenn wir ganz viele elif haben und immer den Wert der selben Variable überprüfen müssen,
dann sind match Statements weit aus geeigneter als if.
String
match können wir mit jeder Art von Datentyp benutzen. Hier zum Beispiel einmal ein match mit einem String:
match greeting:
case "hi":
print("hi whats up!")
case "hello":
print("hello how is your day?")
case _:
print("sorry sir i didn't get you")
Und als if-else würde es dann so aussehen:
if greeting == "hi":
print("hi whats up!")
elif greeting == "hello":
print("hello how is your day?")
else:
print("sorry sir i didn't get you")
Grouping
Bis jetzt haben wir nach einem Wert einen Codeblock eines cases ausgeführt. Wir können aber auch mehrere cases in einen case zusammenfassen, um dann ein Codeblock auszuführen.
match x:
case 10 | 20 | 30:
print("x is either 10, 20 or 30")
case _:
print("i dont know")
Mit if-else würde es dann so aussehen:
if x == 10 or x == 20 or x == 30:
print("x is either 10, 20 or 30")
else:
print("i dont know")
Mit if statement
Zum guten Schluss, um deinen Kopf nochmal explodieren zu lassen, können wir auch match und if gleichzeitg verwenden, um noch komplexere cases definieren zu können.
match x:
case x_even if x % 2 == 0:
print(x_even, "is even")
case _:
print(x, "is not even")
Ohne match und nur mit if-else würde das dann so aussehen:
if x % 2 == 0:
x_even = x
print(x_even, "is even")
else:
print(x, "is not even")
Man könnte argumentieren, dass wenn man schon if-else in einem match benutzt, dass dann der reine if-else Code einfacher nachzuvollziehen ist, als der match plus if-else Code. Am Ende des Tages kommt es auf persönliche Präferenzen, welches du bevorzugt, aber ein Vorteil von match plus if-else ist, dass wir ganz viele cases untereinander auflisten können und falls wir mal für einen case die Vorteile von if-else brauchen, dann können wir das ganz easy, ohne großartig unseren kompletten Code neuzuschreiben. Dadurch haben wir das beste von beiden Welten.
Mit Listen
Wir können auch match mit einer Liste verwenden:
match my_list:
case [a, b, c]:
print()
case [a, b, c, d]:
print()
case _:
print()
Mit [a, b, c, d] werden dann auch neue Variablen für je deisen Platz in der Liste erstellt,
auf die wir dann innerhalb des case Codeblockes zugreifen können.
Mit Dictionaries
Das selbe können wir auch mit Dictionaries machen.
match my_dict:
case { "name": name, "age": age }:
# ...
case _:
# ...
Und auch hier wie bei den Listen können wir extra Variablen für jedes Feld erstellen.
Als wir match ganz am Anfang mit Numbers und Strings verwendet haben, haben wir je nach dem Wert der gematchten Variable cases ausgeführt. Diesen Prozess nennt man auch "Value matching".
Aber bei Listen und Dictionaries haben wir nach der Form oder Struktur gematcht, je nachdem wie lang die Liste ist oder welche Felder ein Dictionary hat. Dies nennt man "Strucutal pattern matching" und ist unglaublich hiflreich und macht unser Pythoncode sooo einfach nachzuvollziehen.
Zum Beispiel lass den vorherigen Code mit der Liste und dem Dictionary einmal zu if-else migrieren. Dann siehst du auch was genau ich meine 😀
### Liste
if len(my_list) == 3:
a = my_list[0]
b = my_list[1]
c = my_list[2]
# ...
elif len(my_list) == 4:
a = my_list[0]
b = my_list[1]
c = my_list[2]
d = my_list[3]
# ...
else:
# ...
### Dictionary
if my_dict["name"] is not None and my_dict["age"] is not None:
name = my_dict["name"]
age = my_dict["age"]
# ...
else:
#...
Class
Klassen werden benutzt, um eigene, neue Datentypen zu erstellen. Klassen sind dabei extrem mächtig und egal was du programmierst, irgendwann willst du Klassen benutzen, um dein Code zu vereinfachen und besser zu strukturieren.
Lass uns eine "Personen" Klasse erstellen, der wir einen Namen geben können und damit kann sie sich selber vorstellen, indem sie eine Begrüßungstext in die Konsole ausgibt.
class Person:
def __init__(self, name):
self.name = name
def greeting(self):
print("Hi my name is", self.name)
Ich erkläre gleich den Code nochmal genauer, aber zu erst lass uns eine Person erstellen und führen dann die "greeting" Funktion aus.
michael = Person("michael")
michael.greeting()
Hia my name is Michael
Hier haben wir die Variable michael erstellt.
Michael ist eine Instanz der Klasse Person,
dies nennt man auch Objekt.
Also michael ist ein Objekt von der Klasse Person.
Die Klasse Person gibt uns die Funktion greeting zur Verfügung.
Die Funktion greeting wurde mit self markiert,
dadurch können wir auf die Instanz von michael zugreifen.
Das müssen wir machen, weil sonst kommen wir nicht an die Variable name,
die in der __init__ Funktion mit self.name erstellt worden ist.
Aber was zur Hölle ist __init__?!
__init__ ist die aller erste Funktion,
die automatisch beim Erstellen eines neuen Objektes der Klasse ausgeführt wird.
Sprich wenn wir Person() aufrufen, dann wird __init__ auch aufgerufen.
Die __init__ Funktion braucht eigentlich nur einen Parameter,
und zwar self.
self ist dabei die Instanz, die wir gerade erstellen wollen.
Wir brauchen self um Werte,
die wir in der Klasse gespeichert haben wollen,
zu erstellen.
So wie ich es bei der Klasse "Person" gemacht habe.
def __init__(self, name):
self.name = name
Hier __init__(self, name) sage ich,
wenn wir eine neue Person erstellen wollen,
dann will ich auch einen Namen.
Deswegen haben wir Person("michael") oben geschrieben.
"michael" wird der __init__ Funktion weiter gegeben.
Mit self.name = name nehme ich den weitergegebenen Namen und speicher den in self ab,
also bei der Instanz der Klasse, die ich gerade erstelle.
Dadurch kann ich dann in greeting auch auf diesen Namen mit self.name zugreifen.
Wir müssen dafür Python aber auch sagen, dass greeting auf "sich selber" zugreifen möchte
und das machen wir indem wir als ersten Funktionparameter self schreiben.
Wenn eine Funktion self hat, dann können wir nicht nur auf Variablen wie name zugreifen,
sondern wir könnten auch name ändern.
Lass dafür eine change_name Funktion erstellen.
class Person:
def __init__(self, name):
self.name = name
def greeting(self):
print("Hi my name is", self.name)
def change_name(self, new_name):
self.name = new_name
michael = Person("michael")
michael.greeting()
michael.change_name("leon")
michael.greeting()
Hi my name is michael
Hi my name is leon
Eine Funktion muss aber nicht immer self haben.
Wenn eine Funktion self hat, dann wird diese auf das erstellte Objekt aufgerufen,
wie wir es mit "michael" auch gemacht haben:
michael.greeting()
michael.change_name("leon")
michael.greeting()
Zum Beispiel lass eine Funktion auf der Klasse "Person" schreiben,
die kein self benutzt und in die Konsole ausgibt, welche Spezies an Tier eine Person ist.
In einfachen Worten: Gebe "Human" in die Konsole aus.
class Person:
# ...
def species():
print("Human")
Funktionen ohne self können wir entweder auf das erstellte Objekt von Person aufrufen,
oder direkt von der Klasse Person. Also so:
michael.species()
Person.species()
Human
Human
Dadurch dass die Funktion species nicht self benutzt,
können wir diese aufrufen ohne eine neue Instanz davon zu erstellen.
Also es ist egal wo wir es aufrufen.
Du kannst es so machen wir du bock hast.
Und das ist im Grunde genommen alles wichtige, wenn es um Klassen in Python geht. In den nächsten Kapitel zeige ich dir noch wie man Logik von einer Klasse in eine andere Klasse weiter vererben kann.
Vererbung 🚧
Python Projekt aufsetzen
Vorher haben wir bis jetzt nur eine .py Datei erstellt und
darin unser Code reingeschrieben und
mit dem Befehl python <Dateiname.py> konnten wir diesen Code ausführen.
Obwohl dies in etwa 99,9% der Arbeit eines Programmierers entspricht,
sind die restlichen 0,1% auch nicht zu vernachlässigen.
Die restlichen 0,1% sind Packages installieren und deinstallieren. Vielleicht brauchen wir eine bestimmte Python Version für unser Projekt etc. All dies macht das Programm uv für uns mega einfach zu managen.
Für eine genauerer, technische Einleitung, besuche hier die Website von uv:
https:/docs.astral.sh/uv/guides/projects/
Installation
Als erstes müssen wir dafür uv auf unseren Computer installieren. Je nach Plattform kann der Befehl ein bisschen anders sein.
Windows
Auf Windows öffne die CMD Konsole und führe diesen Befehl aus:
pip install uv
macOS und Ubuntu
Auf macOS oder Ubuntu führe diese beiden Befehle im Terminal aus:
pipx install uv
Neues Projekt erstellen
Um ein komplett neues Pythonprojekt zu erstellen,
tippen wir einmal uv init <name> in die Konsole ein.
Für <name> kannst du hier,
wie auch immer du dein Projekt nennen möchtest,
eingeben.
Ich werde mal ein Projekt namens "uv-demo" erstellen. In der cmd-Konsole oder in einem Terminal gebe diesen Befehl hier ein:
uv init uv-demo
Dies erstellt mir einen neuen Ordner mit dem Namen "uv-demo". Mit folgender Dateien- und Ordnerstruktur:
uv-demo/
├── main.py
├── pyproject.toml
├── .python-version
└── README.md
Mit cd uv-demo kommst du dann in den Ordner rein,
um dann von dort aus weitere Befehle ausführen zu können,
aber dazu kommen wir gleich noch,
jetzt erstmal gehen wir mal Schritt für Schritt über die ganzen Dateien in unserem Projekt.
pyproject.toml
Die pyproject.toml hat alle Metadaten von unserem Projekt in sich.
Die automatisch generierte pyproject.toml sieht bei mir so aus:
uv-demo/pyproject.toml:
[project]
name = "uv-demo"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.12"
dependencies = []
Das meißte sollte schon vom Namen her offensichtlich sein,
obwohl diese auch erst wichtig werden,
wenn wir unser Programm irgendwo veröffentlichen wollen.
Mit name definieren den Namen unserers Projektes,
mit version welche Version unser Programm ist,
bei description kommt eine Beschreibung unserers Programmes.
requires-python sagt genau aus welche Version an Python unser Programm braucht.
Mit uv können wir auch eine bestimmte Projekt-eigene Version von Python installieren.
Dies macht arbeiten in einem Team mit verschiedenen Computern und verschiedenen Betriebsystem extrem angenehm.
In dependencies müssen wir gar nichts editieren,
weil hier kommen alle Packages rein,
die wir mit uv für unseren Projekt installieren.
Wie das geht zeige ich dir gleich noch,
aber selber editieren müssen wir hier rein goar nix.
.python-version
In dieser Datei steht nur eine Sache und zwar die Version an Python, die wir speziell für unser Projekt installiert haben wollen.
uv-demo/.python-version:
3.12
Wie ich schon gesagt habe, kann uv für uns auch eine Python Version installieren. Wenn wir zum Beispiel Python für unser Projekt updaten wollen, dann editieren wir einfach diese Datei und fertig! Mega simpel oder nicht!
README.md
In README.md können wir eine Einleitung oder Vorstellung unseres Projektes reinschreiben.
Das ist für uns jetzt komplett uninteressant,
aber wenn wir unser Projekt veröffentlichen wollten,
dann können wir in diese Datei eine Vorstellung reinschreiben und erklären
wie man unseres Projekt installiert und oder benutzt.
main.py
Die wohl wichtigste Datei in unserem ganzen Projekt.
Hier schreiben wir unser Code.
Sozusagen ist das unser "Entrypoint" zu unseren Programm.
Mit uv run main.py starten wir unser Programm.
Wenn ich das einmal hier mache:
uv run main.py
Dann bekomme ich diesen Output hier:
Hello from uv-demo!
Das liegt daran, dass uv schon ein bisschen Code für uns generiert hat. Schauen wir uns den mal auch an!
uv-demo/main.py:
def main():
print("Hello from uv-demo!")
if __name__ == "__main__":
main()
Das main ist die Funktion, die automatisch ausgeführt wird,
wenn wir unser Pythonskript ausführen.
Warum?
Naja wegen der vorletzten Zeile if __name__ == "__main__".
Wenn wir unser Programm ausführen mit uv run main.py oder einfach nur python main.py,
dann ist __name__ gleich "__main__", also wird main() gecallt.
Packagemanagement
Wenn wir jetzt weiter, zum Beispiel im Bereich der Digital Humanities, machen wollen, dann brauchen wir ganz viel Code aus dem Internet, der von anderen Leuten programmiert worden ist. Denn es ist viel viel einfacher Code aus dem Internet runterzuladen, um zum Beispiel Daten aus einer Datei, einer Datenbank oder von einer Website zu extrahieren. Wir könnten auch all dies auch selber von Hand schreiben, aber warum, wenn schon einer die Lösung im Internet hochgeladen hat.
Zum Beispiel so installieren wir "ntlk", welches wir in den zukünftigen Kapiteln nutzen, um Texte zu analysieren:
uv add nltk
Mega einfach oder nicht?
"nltk" wurde dabei lokal in unserem Projekt installiert, sodass es keine Konflikte mit anderen Pythonprojekten geben kann, die zum Beispiel eine andere Version von "nltk" benötigen.
uv trackt dabei alle Packages,
die wir geaddet haben, in der pyproject.toml unter [dependencies].
uv-demo/pyproject.toml:
...
dependencies = [
"nltk (>=3.9.1,<4.0.0)"
]
...
Und so entfernen wir "nltk" wieder:
uv remove nltk
Und damit ist jetzt auch wieder nltk von den dependencies unseren Projektes entfernt worden.
Und das wars schon.
Digital Humanities
Digital Humanities (DH) auf Deutsch übersetzt ist "Digitale Geistenswisschenschaft". Aber ein großes Problem ist, dass niemand genau zu 100% sagen kann was DH ist. Es ist schwierig zu sagen wo DH anfängt und wo es endet.
Wordcloud
einfache Wordcloud
Hier in diesem Kapitel werde ich dir zeigen,
wie wir ganz schnell und einfach eine Wordcloud von einem Buch generieren können.
Dabei ist es egal welches Buch du dafür nimmst.
Es sollte aber am Besten ein Englisches sein,
da es Unterschiede zwischen Sprachen geben kann,
auf die wir achten müssten,
wenn wir damit eine Wordcloud erstellen wollen.
Für meine Wordcloud benutzte ich "Japan: An Attempt at Interpretation" von Lafcadio Hearn,
welches ich als .txt Datei aus dem Internet runtergeladen habe.
Zu aller erst erstelle ich ein neues Projekt,
genau so wie wir es in
Kapitel: Python Projekt aufsetzen
gemacht haben.
Die .txt Datei packe ich dann in ein neuen Ordner, namens "books",
den ich in mein neuen Projekt erstellt habe.
Mein Projekt, welches ich auch "simple_wordcloud" genannt habe,
sieht dementsprechen jetzt so aus:
simple_wordcloud/
├── books
│ └── lafcadio.txt
├── main.py
├── pyproject.toml
├── .python-version
└── README.md
Jetzt installieren wir noch alle Packages, die wir für eine Wordcloud brauchen werden:
uv add wordcloud matplotlib
Nun können wir diese beiden Packages in unserem Code importieren:
simple_wordcloud/main.py:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
Hier habe ich WordCloud von dem Package wordcloud und
pyplot von matplotlib importiert.
Dabei habe ich pyplot zu plt umbenannt,
damit ich später nicht immer pyplot komplett austippen muss,
sondern einfach nur plt.
Als aller ersten Schritt müssen wir in der main Funktion unser Buch einlesen und
als String in einer Variable erstmal zwischenspeichern.
simple_wordcloud/main.py:
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
Mit der Funktion open geben wir den relativen Pfad innerhalb unseres Projektes zu einer Datei,
die wir sprichwörtlich "öffnen" wollen.
Mit "r" sagen wir, dass wir diese Datei nur lesen wollen und nicht vorhaben den Inhalt der Datei zu bearbeiten.
Mit f.read() lesen wir dann den kompletten Inhalt der Datei als String.
Und zum guten Schluss, schließen wir die geöffnete Datei,
damit wir nicht unnötig Resourcen vom Computer blockieren,
die auch andersweitig verwendet werden könnten.
Das wars auch schon fast. Jetzt können wir eine Wordcloud daraus erstellen.
simple_wordcloud/main.py:
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
wordcloud = WordCloud().generate(book)
plt.imshow(wordcloud)
plt.show()
Mit WordCloud() initialisieren wir eine WordCloud.
Die generate Funktion generiert dann eine neue WordCloud aus dem Text,
den wir ihr gegeben haben.
plt.imshow(wordcloud) nimmt die generierte Wordcloud und zeigt diese als ein Image grafisch dar,
beziehungsweise wird die Wordcloud hier noch nicht gezeigt,
sondern einer "Warteliste" hinzugefügt und mit plt.show() werden dann alle "Aufträge"
von der "Warteliste" grafisch in einem neuen Fenster dargestellt.
Wenn wir jetzt uv run main.py in der Konsole ausführen,
dann sehen wir solch eine Wordcloud:
Diese Wordcloud sieht aber ein bisschen hässlich aus, oder?
Wir können der WordCloud noch mehr Informationen geben, um diese hübscher zu machen. Hier mal ein Beispiel:
def main():
# ...
wordcloud = WordCloud(
background_color = "white",
height = 1000,
width = 1000,
).generate(book)
# ...
Als erstes mache ich den Hintergrund weiß und die Höhe und Weite zu 1000px, damit unsere Wordcloud eine höhere Auflösung hat und nicht mehr so verschwommen aussieht.
Somit sieht unsere Wordcloud jetzt viel besser aus:
Speicher Wordcloud als .png
Mit plt.show() zeigen wir zwar die Wordcloud grafisch in einem Fenster
und ich könnte jetzt davon ein Screenshot machen,
um es zum Beispiel in meiner Hausarbeit zu verwenden,
aber dies geht auch viel viel besser.
Die to_file Funktion von WordCloud erlaubt es uns,
eine generierte WordCloud als png, jpg/jpeg, svg oder pdf abzuspeichern.
Zum Beispiel hier speichere ich die Wordcloud als png in den Ordner "ouput", den ich in meinen Projekt erstellt habe, ab:
def main():
# ...
wordcloud.to_file("output/cloud_simple.png")
# ...
Am Ende sieht der ganze Code alles zusammen dann so aus:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
wordcloud = WordCloud(
background_color = "white",
height = 1000,
width = 1000,
).generate(book)
wordcloud.to_file("output/cloud_simple.png")
plt.imshow(wordcloud)
plt.show()
komplizierte Wordcloud
Die "einfache" Wordcloud, die wir letzten Kapitel erstellt haben, geht auch noch viel besser und genaurer, denn zB. die "einfache" Wordcloud macht keinen Unterschied, wie Wörter geschrieben worden sind. Groß- und Kleinschreibung ist zwar kein Problem. Die Wordcloud kann automatisch erkennen, dass "japan" und "Japan" das selbe Wort ist, aber Wörter, die von der Bedeutung ähnlich sind, aber komplett anders geschrieben sind, wie zB. "good" und "better", werden als zwei komplett verschiedene Wörter betrachtet, was nicht unbedingt schlimm ist, aber wir können mit dem Package "nltk" alle Wörter zu deren Stammversion zurücksetzen, damit "good" und "better" ein und das selbe Wort ist.
Lass uns dafür ein neues Projekt "complicated_wordcloud" erstellen. Als nächstes installieren wir alle Packages, die wir dafür brauchen werden.
uv add wordcloud matplotlib nltk
Wie in der "einfachen" Wordcloud müssen wir erstmal das Buch lesen.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import nltk
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
Jetzt können wir mit nltk anfangen den Inhalt des Buches, welches wir in die "book" Variable abgespeichert haben, zu reinigen, sprich unnötige Wörter entfernen und dann alle Wörter zu "stemmen" (in die Stammform bringen).
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import nltk
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
nltk.download("all")
tokens = nltk.tokenize.word_tokenize(book)
Hier downloadedn wir alles was nltk braucht, um zu funktionieren. Alles zu downloaden ist ein bisschen overkill, aber so ist es einfacher als dir erklären, was genau du downloaden musst.
Und dann "tokenisieren" wir "book", also wir machen aus den Fließtext von "book" eine Liste von Tokens.
Ein Token bedeutet hier ein Wort.
Man nennt dies "Token",
da ein Token nicht immer nur ein Wort sein muss.
nlkt erlaubt es uns auch mit nltk.tokenize.sent_tokenize aus jeden Satz einen Token zu machen,
aber das macht für eine Wordcloud gar kein Sinn,
deswegen benutzen wir die word_tokenize Funktion.
['JAPAN', 'AN', 'ATTEMPT', 'AT', 'INTERPRETATION', 'BY', 'LAFCADIO', 'HEARN', '1904', 'Contents', 'CHAPTER', 'PAGE', 'I', '.', 'DIFFICULTIES', '.........................', '1', 'II', '.', 'STRANGENESS', 'AND', 'CHARM', '................', '5', 'III', '.', 'THE', 'ANCIENT', 'CULT', '....................', '21', 'IV', '.', 'THE', 'RELIGION', 'OF', 'THE', 'HOME', '............', '33', ...]
Als nächstes entfernen wir alle "stopwords". Stopwords sind Wörter, die keinen signifikanten Inhalt bieten. Zum Beispiel Wörter wie "und", "als", "dennoch", usw. Diese Wörter sind zwar grammatikalisch wichtig, aber nicht für eine Wordcloud...
Mit nltk bekommen wir zB. so alle stopwords aus der englischen Sprache:
nltk.corpus.stopwords.words("english")
['a', 'about', 'above', 'after', 'again', 'against', 'ain', 'all', 'am', 'an', 'and', 'any', 'are', 'aren', "aren't", 'as', 'at', 'be', 'because', 'been', 'before', 'being', 'below', 'between', 'both', 'but', 'by', 'can', 'couldn', "couldn't", 'd', 'did', 'didn', "didn't", 'do', 'does', 'doesn', "doesn't", 'doing', 'don', "don't", 'down', 'during', 'each', 'few', 'for', 'from', 'further', 'had', 'hadn', "hadn't", 'has', 'hasn', "hasn't", 'have', 'haven', "haven't", 'having', 'he', "he'd", "he'll", 'her', 'here', 'hers', 'herself', "he's", 'him', 'himself', 'his', 'how', 'i', "i'd", 'if', "i'll", "i'm", 'in', 'into', 'is', 'isn', "isn't", 'it', "it'd", "it'll", "it's", 'its', 'itself', "i've", 'just', 'll', 'm', 'ma', 'me', 'mightn', "mightn't", 'more', 'most', 'mustn', "mustn't", 'my', 'myself', 'needn', "needn't", 'no', 'nor', 'not', 'now', 'o', 'of', 'off', 'on', 'once', 'only', 'or', 'other', 'our', 'ours', 'ourselves', 'out', 'over', 'own', 're', 's', 'same', 'shan', "shan't", 'she', "she'd", "she'll", "she's", 'should', 'shouldn', "shouldn't", "should've", 'so', 'some', 'such', 't', 'than', 'that', "that'll", 'the', 'their', 'theirs', 'them', 'themselves', 'then', 'there', 'these', 'they', "they'd", "they'll", "they're", "they've", 'this', 'those', 'through', 'to', 'too', 'under', 'until', 'up', 've', 'very', 'was', 'wasn', "wasn't", 'we', "we'd", "we'll", "we're", 'were', 'weren', "weren't", "we've", 'what', 'when', 'where', 'which', 'while', 'who', 'whom', 'why', 'will', 'with', 'won', "won't", 'wouldn', "wouldn't", 'y', 'you', "you'd", "you'll", 'your', "you're", 'yours', 'yourself', 'yourselves', "you've"]
Oder hier einmal alle stopwords von der deutschen Sprache:
nltk.corpus.stopwords.words("german")
['aber', 'alle', 'allem', 'allen', 'aller', 'alles', 'als', 'also', 'am', 'an', 'ander', 'andere', 'anderem', 'anderen', 'anderer', 'anderes', 'anderm', 'andern', 'anderr', 'anders', 'auch', 'auf', 'aus', 'bei', 'bin', 'bis', 'bist', 'da', 'damit', 'dann', 'der', 'den', 'des', 'dem', 'die', 'das', 'dass', 'daß', 'derselbe', 'derselben', 'denselben', 'desselben', 'demselben', 'dieselbe', 'dieselben', 'dasselbe', 'dazu', 'dein', 'deine', 'deinem', 'deinen', 'deiner', 'deines', 'denn', 'derer', 'dessen', 'dich', 'dir', 'du', 'dies', 'diese', 'diesem', 'diesen', 'dieser', 'dieses', 'doch', 'dort', 'durch', 'ein', 'eine', 'einem', 'einen', 'einer', 'eines', 'einig', 'einige', 'einigem', 'einigen', 'einiger', 'einiges', 'einmal', 'er', 'ihn', 'ihm', 'es', 'etwas', 'euer', 'eure', 'eurem', 'euren', 'eurer', 'eures', 'für', 'gegen', 'gewesen', 'hab', 'habe', 'haben', 'hat', 'hatte', 'hatten', 'hier', 'hin', 'hinter', 'ich', 'mich', 'mir', 'ihr', 'ihre', 'ihrem', 'ihren', 'ihrer', 'ihres', 'euch', 'im', 'in', 'indem', 'ins', 'ist', 'jede', 'jedem', 'jeden', 'jeder', 'jedes', 'jene', 'jenem', 'jenen', 'jener', 'jenes', 'jetzt', 'kann', 'kein', 'keine', 'keinem', 'keinen', 'keiner', 'keines', 'können', 'könnte', 'machen', 'man', 'manche', 'manchem', 'manchen', 'mancher', 'manches', 'mein', 'meine', 'meinem', 'meinen', 'meiner', 'meines', 'mit', 'muss', 'musste', 'nach', 'nicht', 'nichts', 'noch', 'nun', 'nur', 'ob', 'oder', 'ohne', 'sehr', 'sein', 'seine', 'seinem', 'seinen', 'seiner', 'seines', 'selbst', 'sich', 'sie', 'ihnen', 'sind', 'so', 'solche', 'solchem', 'solchen', 'solcher', 'solches', 'soll', 'sollte', 'sondern', 'sonst', 'über', 'um', 'und', 'uns', 'unsere', 'unserem', 'unseren', 'unser', 'unseres', 'unter', 'viel', 'vom', 'von', 'vor', 'während', 'war', 'waren', 'warst', 'was', 'weg', 'weil', 'weiter', 'welche', 'welchem', 'welchen', 'welcher', 'welches', 'wenn', 'werde', 'werden', 'wie', 'wieder', 'will', 'wir', 'wird', 'wirst', 'wo', 'wollen', 'wollte', 'würde', 'würden', 'zu', 'zum', 'zur', 'zwar', 'zwischen']
Um jetzt die stopwords aus unseren tokens herauszufiltern,
müssen wir erstmal alle tokens kleinbuchstabig machen.
tokens = [token.casefold() for token in tokens]
Anstelle .casefold() hätten wir auch .lower() verwenden können,
aber .casefold() funktioniert mit allen Sprachen und deren Sonderzeichen,
... hust Deutsch hust.
['japan', 'an', 'attempt', 'at', 'interpretation', 'by', 'lafcadio', 'hearn', '1904', 'contents', 'chapter', 'page', 'i', '.', 'difficulties', '.........................', '1', 'ii', '.', 'strangeness', 'and', 'charm', '................', '5', 'iii', '.', 'the', 'ancient', 'cult', '....................', '21', 'iv', '.', 'the', 'religion', 'of', 'the', 'home', '............', '33', ...]
Jetzt können wir alle stopwords aus tokens rausfiltern.
stopwords = nltk.corpus.stopwords.words("english")
tokens = [token for token in tokens if not token in stopwords]
Ok jetzt fehlt nur noch das "stemmen". Der "PorterStemmer" ist bei englischen Texten der beliebteste, also lass uns den verwenden. nltk bietet den uns auch gleich schon an!
stemmer = nltk.stem.PorterStemmer()
tokens = [stemmer.stem(token) for token in tokens]
['japan', 'attempt', 'at', 'interpret', 'by', 'lafcadio', 'hearn', '1904', 'content', 'chapter', 'page', 'i', '.', 'difficulti', '.........................', '1', 'ii', '.', 'strang', 'and', 'charm', '................', '5', 'iii', '.', 'the', 'ancient', 'cult', '....................', '21', 'iv', '.', 'the', 'religion', 'of', 'the', 'home', '............', '33', 'v.', ...]
Et voila!
Wir sind fertig!
Jetzt können wir aus diesen Tokens eine Wordcloud erstellen.
Aber halt stopp!
Die WordCloud.generate() Funktion erlaubt nur Text in Form eines Strings
und nicht in Form einer Liste von Tokens.
Lass uns erstmal alle tokens wieder zu einem einzigen Fließtext kombinieren.
text = " ".join(tokens)
" ".join(tokens) kombiniert alle tokens zu einem String
mit einem Leerzeichen zwischen jeden einzelnen Token.
Und so können wir es jetzt,
genau so wie in der "einfachen" Wordcloud gemacht haben,
der generate Funktion weiter geben.
WordCloud(
background_color = "white",
height = 1000,
width = 1000,
).generate(text)
Am Ende sieht unser kompletter Code so hier aus:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import nltk
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
nltk.download("all")
tokens = nltk.tokenize.word_tokenize(book)
stopwords = nltk.corpus.stopwords.words("english")
tokens = [token.casefold() for token in tokens]
tokens = [token for token in tokens if token not in stopwords]
stemmer = nltk.stem.PorterStemmer()
tokens = [stemmer.stem(token) for token in tokens]
text = " ".join(tokens)
wordcloud = WordCloud(
background_color = "white",
height = 1000,
width = 1000,
).generate(text)
wordcloud.to_file("output/cloud_comlicated.png")
plt.imshow(wordcloud)
plt.show()
Und unsere generierte Wordcloud so:
hübsche Wordcloud
Eine Wordcloud ist das perfekte Tool, um visuell und hübsch anderen zu zeigen, um was es in einem Buch geht oder welche Wörter ein Autor bevorzugt. Aber bis jetzt sehen unsere Wordclouds ziemlich langweilig und viereckig aus, oder nicht? In diesem Kapitel werde ich dir zeigen, wie du deine Wordcloud zB. so aussehen lassen kannst.
Wir starten dabei ab den Ende von dem
Kapitel der "einfachen" Wordcloud,
also sieht unsere main.py so aus:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
wordcloud = WordCloud(
background_color = "white",
height = 1000,
width = 1000,
).generate(book)
wordcloud.to_file("output/cloud_pretty.png")
plt.imshow(wordcloud)
plt.show()
Damit unsere Wordcloud wie Japan aussieht, brauchen wir eine sogenannte Makse (oder Mask auf Englisch). Eine Maske ist nichts anderes als ein Schwarz-Weiß-Bild. Alle Pixel die in der Maske schwarz sind, dort wird die Wordcloud versuchen Wörter reinzuschreiben. Du kannst eine Maske selber mit Photoshop, MS Paint oder Gimp malen oder meine hier einfach downloaden und in den assets Ordner reinkopieren.
Mein Projektordner sieht damit jetzt so aus:
pretty_wordcloud/
├── books
│ └── lafcadio.txt
├── main.py
├── pyproject.toml
├── .python-version
└── README.md
So jezt haben wir alles vorbereitet und wir können wir uns ans coden machen! Als erstes müssen wir das Package numpy installieren (neber den ganzen anderen Packages, die wir im Kapitel: einfache Wordcloud installiert haben)
uv add numpy
Und natürlich auch in unserem Code importieren.
Um die Makse in unseren Code einlesen zu können,
müssen wir auch noch PIL.Image importieren,
welches schon standardmäßig mit Python mitgeliefert wird,
also müssen wir dafür nichts installieren.
import PIL.Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
Jetzt lesen wir die Maske ein und konvertieren es zu einem numpy.array,
weil WordCloud es sonst nicht akzeptiert.
japan_mask = np.array(Image.open("assets/japan_mask.png"))
wordcloud = WordCloud(
mask = japan_mask,
contour_color = "black",
contour_width = 2,
background_color = "white",
random_state = 5,
).generate(text)
Wie du am Codeausschnitt sehen kannst,
habe ich noch contour_color und contour_width definiert.
Diese bestimmen den Rand der Maske,
wie viele Pixel dick und welche Farbe der Rand haben soll.
height und width habe ich auch rausgenommen,
da dies jetzt von der Größe der Maske bestimmt wird.
Bei einer WordCloud wird die Position der einzelnen Wörter immer zufällig bestimmt.
Wenn wir den Parameter random_state festlegen, dann ist dieser Zufall nicht mehr zufällig.
Damit gehen wir sicher, dass unsere WordCloud immer gleich aussieht,
egal wann wir diese generieren.
Dabei ist es egal auf welcher Zahl wir random_state setzen,
wichtig ist nur, dass er auf einer Zahl gesetzt ist.
Vorallem wenn wir unsere WordCloud hübscher machen wollen,
wird uns das ernorm helfen,
da alle Wörter immer an der selben Stelle sind.
Als letzten Touch,
um die Wordcloud noch hübscher zu machen,
möchte ich die Font und Farben der Wörter anpassen.
Für die Font downloade ich einfach eine von der
Google Font Website
und speicher diese in den assets Ordner.
Ich habe zum Beispiel die Hanuman-VariableFont_wght.ttf Font runtergeladen und mein Projektordner sieht jetzt so aus:
pretty_wordcloud/
├── books
│ ├── Hanuman-VariableFont_wght.ttf
│ ├── japan_mask.png
│ └── lafcadio.txt
├── main.py
├── pyproject.toml
├── .python-version
└── README.md
Um die Farben der Wörter in der Cloud anzupassen,
können wir matplotlib.colormaps verwenden.
matplotlib bietet ganz viele verschiedene colormaps an,
die du auf deren Website
anschauen kannst.
In diesem Fall möchte ich ich colormap "Reds" verwenden.
wordcloud = WordCloud(
mask = japan_mask,
contour_color = "black",
contour_width = 2,
background_color = "white",
colormap = colormaps["Reds"],
font_path = "assets/Hanuman-VariableFont_wght.ttf",
random_state = 5,
).generate(text)
Somit sieht unser ganzer Code jetzt so aus:
import PIL.Image
import numpy as np
from matplotlib import colormaps
import matplotlib.pyplot as plt
from wordcloud import WordCloud
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
japan_mask = np.array(Image.open("assets/japan_mask.png"))
wordcloud = WordCloud(
mask = japan_mask,
contour_color = "black",
contour_width = 2,
background_color = "white",
colormap = colormaps["Reds"],
font_path = "assets/Hanuman-VariableFont_wght.ttf",
random_state = 5,
).generate(text)
wordcloud.to_file("output/cloud_pretty.png")
plt.imshow(wordcloud)
plt.show()
Und unsere Wordcloud genau so wie von ganz oben aus:
Cool oder nicht? Und das schöne ist, du weißt jetzt wie du deine ganz eigene Wordcloud für deine Hausarbeit erstellen kannst.
Sentiment analysis
Wikipedia
Erkläre nochmal Twitter, Social Media, Amazon, Produktrezessionen
Vader nicht LLM Roberta mit LLM
erstmal Vader
VADER analysis 🚧
Hier einmal ein Zitat vom Author von dem Vader Packetes, wo er erklärt was Vader genau ist:
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media.
Auf Deutsch übersetzt bedeutet, dass Vader im Grunde genommen nichts anderes als ein Lexicon ist, in dem jedes Wort einen Score hat. Der Score drückt aus wie positiv, negativ oder neutral ein Wort ist und am Ende wir jedes Wort zusammen gerechnet, um herauszufinden in welcher Gefühlslage ein Text ist.
Wichtig ist, dass Vader für kurze Texte optimiert ist, wie man es von Sozialen Medien oder Amazon Produktrezessionen kennt. Ein komplettes Buch sollten wir damit nicht analysieren, weil es durch die große Menge an Text immer als sehr neutral eingestuft wird, egal wie negativ die Schreibweise eines Authors ist. Zum Beispiel habe ich hier einmal Vader für George Orwells "1984" angewendet:
Obwohl "1984" sich durch und durch mit dystopischen Elementen bedient, können wir sehen, dass Vader denkt, dass es sehr neutral ist. Das liegt daran, dass in einem Roman, im Gegensatz zu einer Produkt- oder Filmbewertung, Szenen ausführlich beschreiben werden und daher sehr viele "neutrale" Wörter verwendet werden. Egal wie dystopisch oder düster ein Roman ist, Vader wird es immer als sehr neutral einstufen.
Also Vader ist super für kurze Texte, wie Kommentar, Tweats, Produktreviews, Briefe oder Zeitungsartikel, aber blöd für lange Texte wie wissenschaftliche Artikel, Bücher oder Romane.
Vader aufzusetzen ist sehr einfach. Wir müssen dafür nur nltk installieren:
uv add nltk
Dann können wir Vaders Sentiment Analyzer von nltk importieren.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
Und jetzt initialiseren wir den Analyzer.
sia = SentimentIntensityAnalyzer()
Um darauf dann die polarity_scores Funktion aufrufen zu können,
um dann wiederum das Sentiment eines Textes herauszufinden.
Wenn ich das einmal für den Text "This is the best day ever" ausführe, dann bekomme ich dieses Resultat
sia = SentimentIntensityAnalyzer()
scores = sia.polarity_scores("This is the best day ever")
print(scores)
{'neg': 0.0, 'neu': 0.543, 'pos': 0.457, 'compound': 0.6369}
Wir haben hier ein Dictionary mit "neg" für negativ, "neu" für neutral, "pos" für positiv und "compound" für einen kumullierten Wert, der ausdrückt wie positiv oder negativ der eingegebene Text im Ganzen ist.
"neg", "neu", "pos" ist ein Wert zwischen 0 und 1, wo 0 für 0% und 1 für 100% steht. Von unseren Ergebnis können wir erkennen, dass der Text "This is the best day ever" 0% negativ, 54% neutral und 45% positiv ist.
"compound" ist ein Wert zwischen -1 und +1, wo -1 gleich 100% negativ bedeutet, +1 gleich 100% positiv und 0 gleich 100% neutral ist. compound ist super um Anhand einer einzigen Zahl zu erkennen in welcher Gefühlslage ein Text ist. An unserem Ergebnis von oben können wir erkennen, dass unser Text sehr positiv ist.
Lass uns einmal ein negatives Beispiel anschauen. Zum Beispiel der Text "This day was the worst. I'll never go outside again!!!!" gibt uns dieses Ergebnis:
{'neg': 0.369, 'neu': 0.631, 'pos': 0.0, 'compound': -0.7405}
Twitter Sentiment Analyse
Aber gut, wir haben Vader aufgesetzt und wir können das Ergebnis interpretieren. Lass als nächstes mal reale Kommentare aus dem Internet nehmen und mit Vader eine Sentiment Analyse machen.
Ich habe hier ein Datenset über TODO vorbereitet, die du hier runterladen kannst:
Tweats.csv sind Tweats von echten Usern, die über TODO getweatet haben und wir werden über jeden einzelnen Post gehen, die Gefühlslage analysieren, wie toll oder blöd der User TODO fand und danach werden wir all diese Daten grafisch plotten, um zu schauen, wie die allgemeine Gefühlslage ist.
ROBERTA analysis 🚧
import pandas as pd
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from scipy.special import softmax
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer, normalize
link = "cardiffnlp/twitter-roberta-base-sentiment"
tokenizer = AutoTokenizer.from_pretrained(link)
model = AutoModelForSequenceClassification.from_pretrained(link)
def main():
# vader = SentimentIntensityAnalyzer()
# print("Vader: ", vader.polarity_scores(example))
data = pd.read_csv("assets/Reviews.csv")
data = data.head(100)
result = {}
for index, row in data.iterrows():
pol = roberta_polarity_scores(row["Text"])
result[index] = {
"score": row["Score"],
"neg": pol["neg"],
"neu": pol["neu"],
"pos": pol["pos"],
}
result = pd.DataFrame(result)
print(result.head())
def roberta_polarity_scores(text):
encoded_text = tokenizer(text, return_tensors="pt")
output = model(**encoded_text)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
scores = {
"neg": scores[0],
"neu": scores[1],
"pos": scores[2],
# TODO compound
}
return scores
Document clustering
Topic modeling
Semantic search
Word embeddings
Contextual embeddings
Japanische Texte
Im Team arbeiten
uv
git
Gitlab
Issues
Merge Requests
Lizenz
Dieses Werk ist lizensiert unter GNU Free Documentation License Version 1.3, 3 November 2008
GNU Free Documentation License
Version 1.3, 3 November 2008
Copyright © 2000, 2001, 2002, 2007, 2008 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
0. PREAMBLE
The purpose of this License is to make a manual, textbook, or other functional and useful document "free" in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
1. APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The "Document", below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as "you". You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A "Modified Version" of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document's overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The "Invariant Sections" are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The "Title Page" means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, "Title Page" means the text near the most prominent appearance of the work's title, preceding the beginning of the body of the text.
The "publisher" means any person or entity that distributes copies of the Document to the public.
A section "Entitled XYZ" means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as "Acknowledgements", "Dedications", "Endorsements", or "History".) To "Preserve the Title" of such a section when you modify the Document means that it remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
2. VERBATIM COPYING
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
3. COPYING IN QUANTITY
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document's license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
- A. Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
- B. List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
- C. State on the Title page the name of the publisher of the Modified Version, as the publisher.
- D. Preserve all the copyright notices of the Document.
- E. Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
- F. Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
- G. Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document's license notice.
- H. Include an unaltered copy of this License.
- I. Preserve the section Entitled "History", Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled "History" in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
- J. Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the "History" section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
- K. For any section Entitled "Acknowledgements" or "Dedications", Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
- L. Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
- M. Delete any section Entitled "Endorsements". Such a section may not be included in the Modified Version.
- N. Do not retitle any existing section to be Entitled "Endorsements" or to conflict in title with any Invariant Section.
- O. Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version's license notice. These titles must be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it contains nothing but endorsements of your Modified Version by various parties—for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled "History" in the various original documents, forming one section Entitled "History"; likewise combine any sections Entitled "Acknowledgements", and any sections Entitled "Dedications". You must delete all sections Entitled "Endorsements".
6. COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an "aggregate" if the copyright resulting from the compilation is not used to limit the legal rights of the compilation's users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document's Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
8. TRANSLATION
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled "Acknowledgements", "Dedications", or "History", the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
9. TERMINATION
You may not copy, modify, sublicense, or distribute the Document except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense, or distribute it is void, and will automatically terminate your rights under this License.
However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice.
Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, receipt of a copy of some or all of the same material does not give you any rights to use it.
10. FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See https://www.gnu.org/licenses/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License "or any later version" applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation. If the Document specifies that a proxy can decide which future versions of this License can be used, that proxy's public statement of acceptance of a version permanently authorizes you to choose that version for the Document.
11. RELICENSING
"Massive Multiauthor Collaboration Site" (or "MMC Site") means any World Wide Web server that publishes copyrightable works and also provides prominent facilities for anybody to edit those works. A public wiki that anybody can edit is an example of such a server. A "Massive Multiauthor Collaboration" (or "MMC") contained in the site means any set of copyrightable works thus published on the MMC site.
"CC-BY-SA" means the Creative Commons Attribution-Share Alike 3.0 license published by Creative Commons Corporation, a not-for-profit corporation with a principal place of business in San Francisco, California, as well as future copyleft versions of that license published by that same organization.
"Incorporate" means to publish or republish a Document, in whole or in part, as part of another Document.
An MMC is "eligible for relicensing" if it is licensed under this License, and if all works that were first published under this License somewhere other than this MMC, and subsequently incorporated in whole or in part into the MMC, (1) had no cover texts or invariant sections, and (2) were thus incorporated prior to November 1, 2008.
The operator of an MMC Site may republish an MMC contained in the site under CC-BY-SA on the same site at any time before August 1, 2009, provided the MMC is eligible for relicensing.
ADDENDUM: How to use this License for your documents
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Copyright (C) YEAR YOUR NAME.
Permission is granted to copy, distribute and/or modify this document
under the terms of the GNU Free Documentation License, Version 1.3
or any later version published by the Free Software Foundation;
with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts.
A copy of the license is included in the section entitled "GNU
Free Documentation License".
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the "with … Texts." line with this:
with the Invariant Sections being LIST THEIR TITLES, with the
Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.
Contributors
Author: Marc Mäurer < marc.maeurer@pm.me >