VADER analysis 🚧
Hier einmal ein Zitat vom Author von dem Vader Packetes, wo er erklärt was Vader genau ist:
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media.
Auf Deutsch übersetzt bedeutet, dass Vader im Grunde genommen nichts anderes als ein Lexicon ist, in dem jedes Wort einen Score hat. Der Score drückt aus wie positiv, negativ oder neutral ein Wort ist und am Ende wir jedes Wort zusammen gerechnet, um herauszufinden in welcher Gefühlslage ein Text ist.
Wichtig ist, dass Vader für kurze Texte optimiert ist, wie man es von Sozialen Medien oder Amazon Produktrezessionen kennt. Ein komplettes Buch sollten wir damit nicht analysieren, weil es durch die große Menge an Text immer als sehr neutral eingestuft wird, egal wie negativ die Schreibweise eines Authors ist. Zum Beispiel habe ich hier einmal Vader für George Orwells "1984" angewendet:
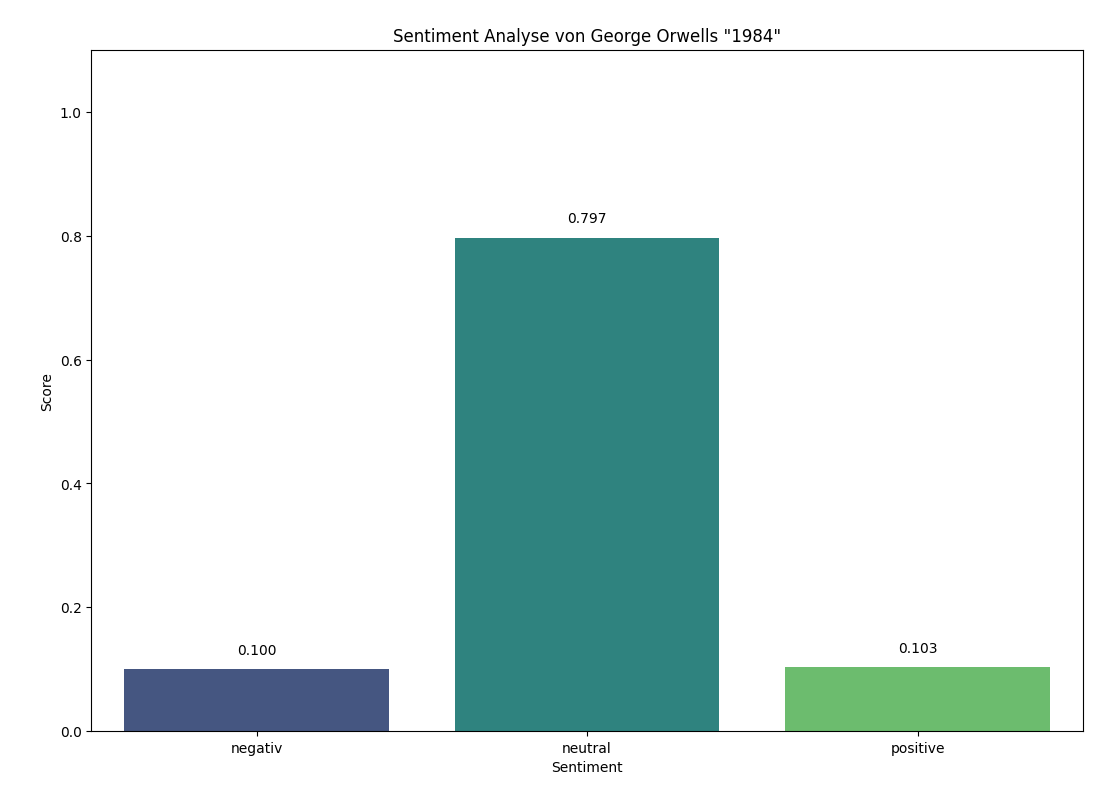
Obwohl "1984" sich durch und durch mit dystopischen Elementen bedient, können wir sehen, dass Vader denkt, dass es sehr neutral ist. Das liegt daran, dass in einem Roman, im Gegensatz zu einer Produkt- oder Filmbewertung, Szenen ausführlich beschreiben werden und daher sehr viele "neutrale" Wörter verwendet werden. Egal wie dystopisch oder düster ein Roman ist, Vader wird es immer als sehr neutral einstufen.
Also Vader ist super für kurze Texte, wie Kommentar, Tweats, Produktreviews, Briefe oder Zeitungsartikel, aber blöd für lange Texte wie wissenschaftliche Artikel, Bücher oder Romane.
Vader aufzusetzen ist sehr einfach. Wir müssen dafür nur nltk installieren:
uv add nltk
Dann können wir Vaders Sentiment Analyzer von nltk importieren.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
Und jetzt initialiseren wir den Analyzer.
sia = SentimentIntensityAnalyzer()
Um darauf dann die polarity_scores Funktion aufrufen zu können,
um dann wiederum das Sentiment eines Textes herauszufinden.
Wenn ich das einmal für den Text "This is the best day ever" ausführe, dann bekomme ich dieses Resultat
sia = SentimentIntensityAnalyzer()
scores = sia.polarity_scores("This is the best day ever")
print(scores)
{'neg': 0.0, 'neu': 0.543, 'pos': 0.457, 'compound': 0.6369}
Wir haben hier ein Dictionary mit "neg" für negativ, "neu" für neutral, "pos" für positiv und "compound" für einen kumullierten Wert, der ausdrückt wie positiv oder negativ der eingegebene Text im Ganzen ist.
"neg", "neu", "pos" ist ein Wert zwischen 0 und 1, wo 0 für 0% und 1 für 100% steht. Von unseren Ergebnis können wir erkennen, dass der Text "This is the best day ever" 0% negativ, 54% neutral und 45% positiv ist.
"compound" ist ein Wert zwischen -1 und +1, wo -1 gleich 100% negativ bedeutet, +1 gleich 100% positiv und 0 gleich 100% neutral ist. compound ist super um Anhand einer einzigen Zahl zu erkennen in welcher Gefühlslage ein Text ist. An unserem Ergebnis von oben können wir erkennen, dass unser Text sehr positiv ist.
Lass uns einmal ein negatives Beispiel anschauen. Zum Beispiel der Text "This day was the worst. I'll never go outside again!!!!" gibt uns dieses Ergebnis:
{'neg': 0.369, 'neu': 0.631, 'pos': 0.0, 'compound': -0.7405}
Twitter Sentiment Analyse
Aber gut, wir haben Vader aufgesetzt und wir können das Ergebnis interpretieren. Lass als nächstes mal reale Kommentare aus dem Internet nehmen und mit Vader eine Sentiment Analyse machen.
Ich habe hier ein Datenset über TODO vorbereitet, die du hier runterladen kannst:
Tweats.csv sind Tweats von echten Usern, die über TODO getweatet haben und wir werden über jeden einzelnen Post gehen, die Gefühlslage analysieren, wie toll oder blöd der User TODO fand und danach werden wir all diese Daten grafisch plotten, um zu schauen, wie die allgemeine Gefühlslage ist.