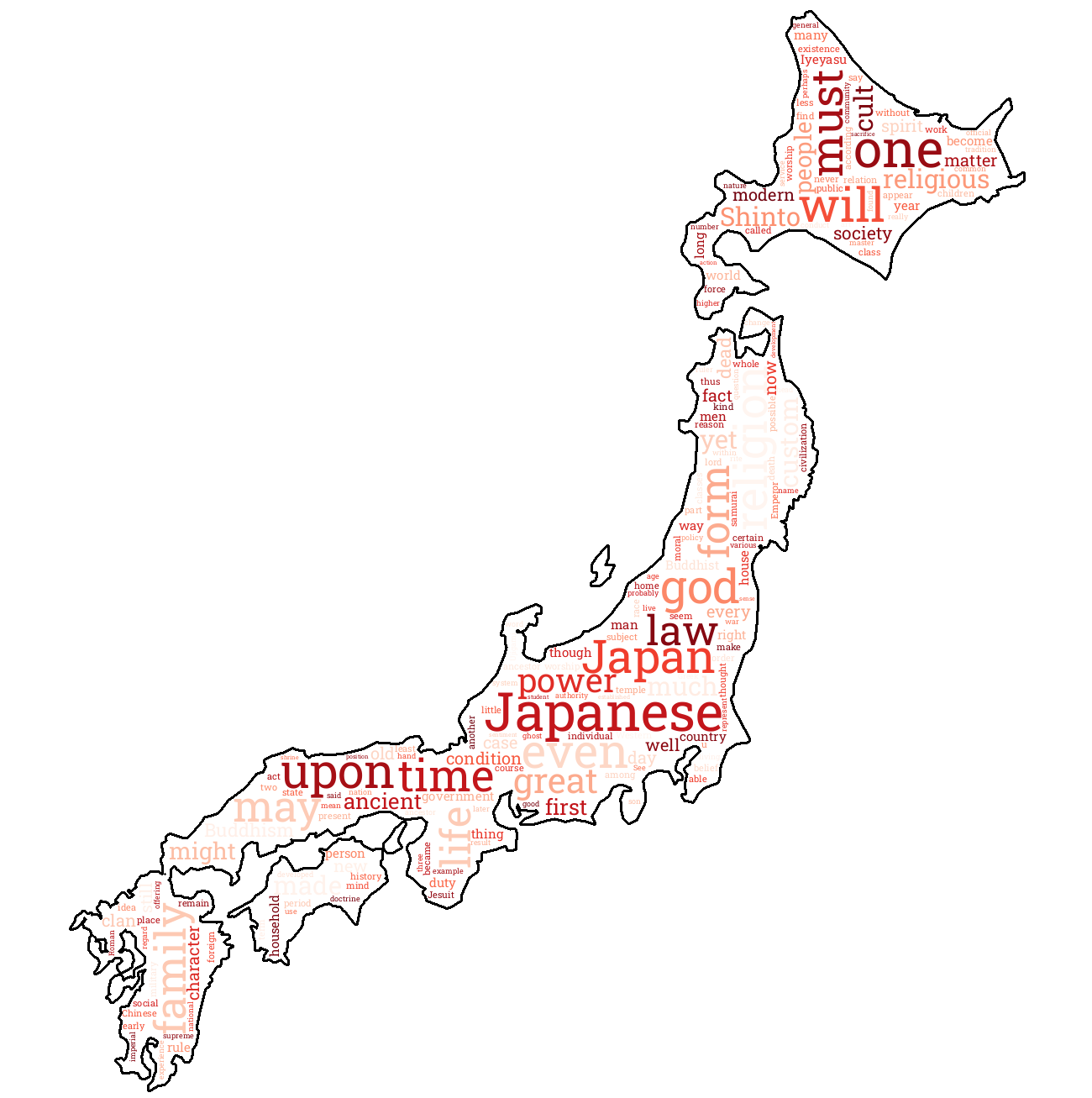
hübsche Wordcloud
Eine Wordcloud ist das perfekte Tool, um visuell und hübsch anderen zu zeigen, um was es in einem Buch geht oder welche Wörter ein Autor bevorzugt. Aber bis jetzt sehen unsere Wordclouds ziemlich langweilig und viereckig aus, oder nicht? In diesem Kapitel werde ich dir zeigen, wie du deine Wordcloud zB. so aussehen lassen kannst.
Wir starten dabei ab den Ende von dem
Kapitel der "einfachen" Wordcloud,
also sieht unsere main.py so aus:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
wordcloud = WordCloud(
background_color = "white",
height = 1000,
width = 1000,
).generate(book)
wordcloud.to_file("output/cloud_pretty.png")
plt.imshow(wordcloud)
plt.show()
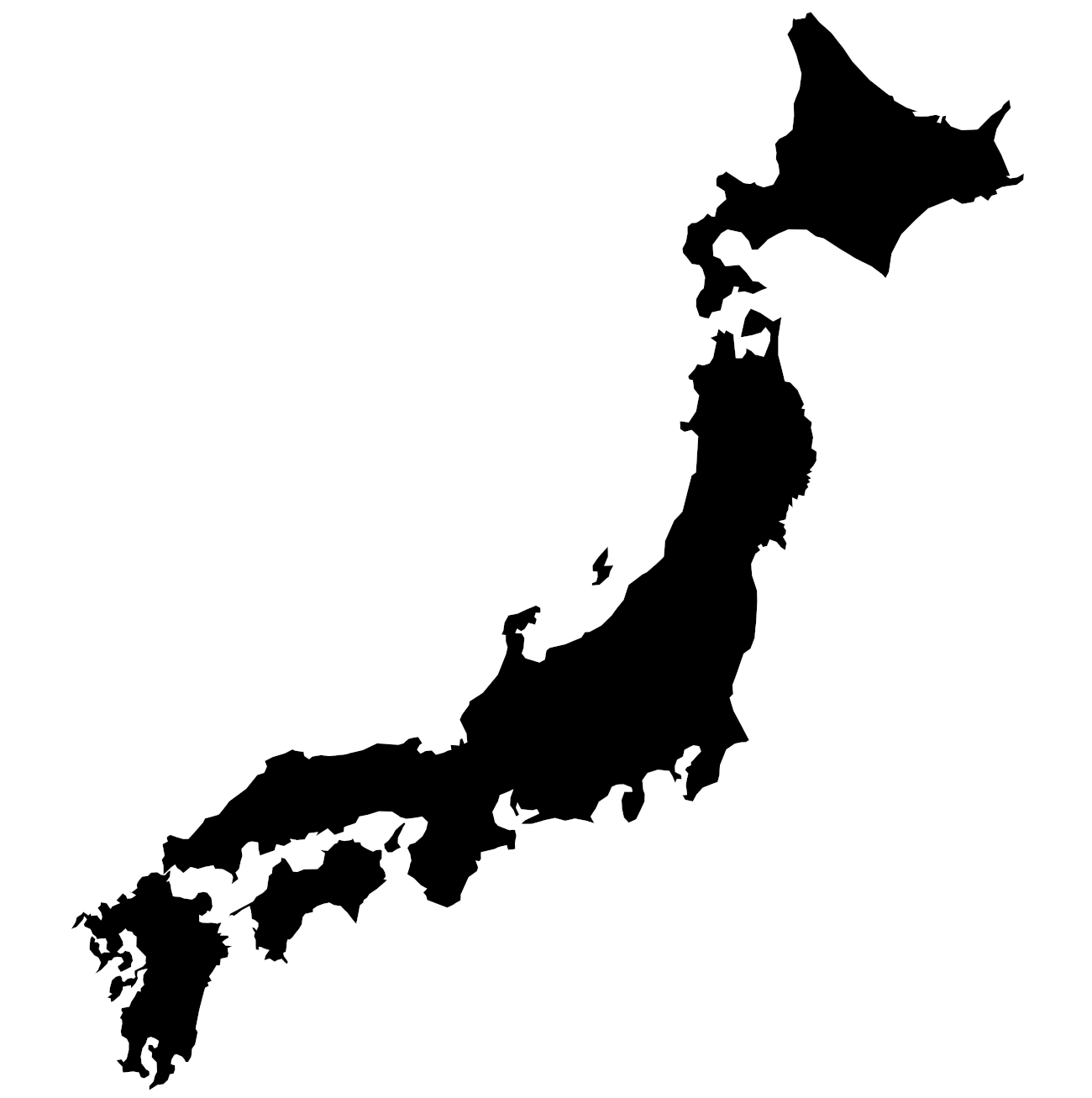
Damit unsere Wordcloud wie Japan aussieht, brauchen wir eine sogenannte Makse (oder Mask auf Englisch). Eine Maske ist nichts anderes als ein Schwarz-Weiß-Bild. Alle Pixel die in der Maske schwarz sind, dort wird die Wordcloud versuchen Wörter reinzuschreiben. Du kannst eine Maske selber mit Photoshop, MS Paint oder Gimp malen oder meine hier einfach downloaden und in den assets Ordner reinkopieren.
Mein Projektordner sieht damit jetzt so aus:
pretty_wordcloud/
├── books
│ └── lafcadio.txt
├── main.py
├── pyproject.toml
├── .python-version
└── README.md
So jezt haben wir alles vorbereitet und wir können wir uns ans coden machen! Als erstes müssen wir das Package numpy installieren (neber den ganzen anderen Packages, die wir im Kapitel: einfache Wordcloud installiert haben)
uv add numpy
Und natürlich auch in unserem Code importieren.
Um die Makse in unseren Code einlesen zu können,
müssen wir auch noch PIL.Image importieren,
welches schon standardmäßig mit Python mitgeliefert wird,
also müssen wir dafür nichts installieren.
import PIL.Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
Jetzt lesen wir die Maske ein und konvertieren es zu einem numpy.array,
weil WordCloud es sonst nicht akzeptiert.
japan_mask = np.array(Image.open("assets/japan_mask.png"))
wordcloud = WordCloud(
mask = japan_mask,
contour_color = "black",
contour_width = 2,
background_color = "white",
random_state = 5,
).generate(text)
Wie du am Codeausschnitt sehen kannst,
habe ich noch contour_color und contour_width definiert.
Diese bestimmen den Rand der Maske,
wie viele Pixel dick und welche Farbe der Rand haben soll.
height und width habe ich auch rausgenommen,
da dies jetzt von der Größe der Maske bestimmt wird.
Bei einer WordCloud wird die Position der einzelnen Wörter immer zufällig bestimmt.
Wenn wir den Parameter random_state festlegen, dann ist dieser Zufall nicht mehr zufällig.
Damit gehen wir sicher, dass unsere WordCloud immer gleich aussieht,
egal wann wir diese generieren.
Dabei ist es egal auf welcher Zahl wir random_state setzen,
wichtig ist nur, dass er auf einer Zahl gesetzt ist.
Vorallem wenn wir unsere WordCloud hübscher machen wollen,
wird uns das ernorm helfen,
da alle Wörter immer an der selben Stelle sind.
Als letzten Touch,
um die Wordcloud noch hübscher zu machen,
möchte ich die Font und Farben der Wörter anpassen.
Für die Font downloade ich einfach eine von der
Google Font Website
und speicher diese in den assets Ordner.
Ich habe zum Beispiel die Hanuman-VariableFont_wght.ttf Font runtergeladen und mein Projektordner sieht jetzt so aus:
pretty_wordcloud/
├── books
│ ├── Hanuman-VariableFont_wght.ttf
│ ├── japan_mask.png
│ └── lafcadio.txt
├── main.py
├── pyproject.toml
├── .python-version
└── README.md
Um die Farben der Wörter in der Cloud anzupassen,
können wir matplotlib.colormaps verwenden.
matplotlib bietet ganz viele verschiedene colormaps an,
die du auf deren Website
anschauen kannst.
In diesem Fall möchte ich ich colormap "Reds" verwenden.
wordcloud = WordCloud(
mask = japan_mask,
contour_color = "black",
contour_width = 2,
background_color = "white",
colormap = colormaps["Reds"],
font_path = "assets/Hanuman-VariableFont_wght.ttf",
random_state = 5,
).generate(text)
Somit sieht unser ganzer Code jetzt so aus:
import PIL.Image
import numpy as np
from matplotlib import colormaps
import matplotlib.pyplot as plt
from wordcloud import WordCloud
def main():
f = open("books/lafcadio.txt", "r")
book = f.read()
f.close()
japan_mask = np.array(Image.open("assets/japan_mask.png"))
wordcloud = WordCloud(
mask = japan_mask,
contour_color = "black",
contour_width = 2,
background_color = "white",
colormap = colormaps["Reds"],
font_path = "assets/Hanuman-VariableFont_wght.ttf",
random_state = 5,
).generate(text)
wordcloud.to_file("output/cloud_pretty.png")
plt.imshow(wordcloud)
plt.show()
Und unsere Wordcloud genau so wie von ganz oben aus:
Cool oder nicht? Und das schöne ist, du weißt jetzt wie du deine ganz eigene Wordcloud für deine Hausarbeit erstellen kannst.